
引言
游戏开发一直是热门的领域,掌握良好的游戏编程模式是开发人员的应备技能,本书细致地讲解了游戏开发需要用到的各种编程模式,并提供了丰富的示例。本章是各个经典设计模式的重访。
《设计模式:可复用面向对象软件的基础》出版已经二十年了。 除非你比我从业还久,否则《设计模式》已经酝酿成一坛足以饮用的老酒了。 对于像软件行业这样快速发展的行业,它已经是老古董了。 这本书的持久流行证明了设计方法比框架和方法论更经久不衰。
虽然我认为设计模式仍然有意义,但在过去几十年我们学到了很多。 在这一部分,我们会遇到 GoF 记载的一些模式。 对于每个模式,我希望能讲些有用有趣的东西。
我认为有些模式被过度使用了(单例模式), 而另一些被冷落了(命令模式)。 有些模式在这里是因为我想探索其在游戏上的特殊应用(享元模式和观察者模式)。 最后,我认为看看有些模式在更广的编程领域是如何运用的是很有趣的(原型模式和状态模式)。
命令模式
命令模式是我最喜欢的模式之一。 大多数我写的游戏或者别的什么之类的大型程序,都会在某处用到它。 当在正确的地方使用时,它可以将复杂的代码清理干净。 对于这样一个了不起的模式,不出所料地,GoF 有个深奥的定义:
将一个请求封装为一个对象,从而使你可用不同的请求对客户进行参数化; 对请求排队或记录请求日志,以及支持可撤销的操作。
我想你也会觉得这个句子晦涩难懂。 第一,它的比喻难以理解。 在词语可以指代任何事物的狂野软件世界之外,“客户” 是一个人 —— 那些和你做生意的人。 据我查证,人类不能被 “参数化”。
然后,句子余下的部分介绍了可能会使用这个模式的场景。 如果你的场景不在这个列表中,那么这对你就没什么用处。 我的命令模式精简定义为:
命令是具现化的方法调用。
“Reify(具现化)” 来自于拉丁语 “res”,意为 “thing”(事物),加上英语后缀 “–fy”。 所以它意为 “thingify”,没准用 “thingify” 更合适。
当然,“精简” 往往意味着着 “缺少必要信息”,所以这可能没有太大的改善。 让我扩展一下。如果你没有听说过 “具现化” 的话,它的意思是 “实例化,对象化”。 具现化的另外一种解释方式是将某事物作为 “第一公民” 对待。
在某些语言中的反射允许你在程序运行时命令式地和类型交互。 你可以获得类的类型对象,可以与其交互看看这个类型能做什么。换言之,反射是具现化类型的系统。
两种术语都意味着将概念变成数据 —— 一个对象 —— 可以存储在变量中,传给函数。 所以称命令模式为 “具现化方法调用”,意思是方法调用被存储在对象中。
这听起来有些像 “回调”,“第一公民函数”,“函数指针”,“闭包”,“偏函数”, 取决于你在学哪种语言,事实上大致上是同一个东西。GoF 随后说:
命令模式是一种回调的面向对象实现。
这是一种对命令模式更好的解释。
但这些都既抽象又模糊。我喜欢用实际的东西作为章节的开始,不好意思,搞砸了。 作为弥补,从这里开始都是命令模式能出色应用的例子。
配置输入
在每个游戏中都有一块代码读取用户的输入 —— 按钮按下,键盘敲击,鼠标点击,诸如此类。 这块代码会获取用户的输入,然后将其变为游戏中有意义的行为:

下面是一种简单的实现:
void InputHandler::handleInput() |
专家建议:不要太经常地按 B。
这个函数通常在游戏循环中每帧调用一次,我确信你可以理解它做了什么。 在我们想将用户的输入和程序行为硬编码在一起时,这段代码可以正常工作,但是许多游戏允许玩家配置按键的功能。
为了支持这点,需要将这些对 jump() 和 fireGun() 的直接调用转化为可以变换的东西。 “变换” 听起来有点像变量干的事,因此我们需要表示游戏行为的对象。进入:命令模式。
我们定义了一个基类代表可触发的游戏行为:
class Command |
当你有接口只包含一个没有返回值的方法时,很可能你可以使用命令模式。
然后我们为不同的游戏行为定义相应的子类:
class JumpCommand : public Command |
在代码的输入处理部分,为每个按键存储一个指向命令的指针。
class InputHandler |
现在输入处理部分这样处理:
void InputHandler::handleInput() |
注意在这里没有检测 NULL 了吗?这假设每个按键都与某些命令相连。
如果想支持不做任何事情的按键又不想显式检测 NULL,我们可以定义一个命令类,它的 execute() 什么也不做。 这样,某些按键处理器不必设为 NULL,只需指向这个类。这种模式被称为空对象。
以前每个输入直接调用函数,现在会有一层间接寻址:

这是命令模式的简短介绍。如果你能够看出它的好处,就把这章剩下的部分作为奖励吧。
角色说明
我们刚才定义的类可以在之前的例子上正常工作,但有很大的局限。 问题在于假设了顶层的 jump(), fireGun() 之类的函数可以找到玩家角色,然后像木偶一样操纵它。
这些假定的耦合限制了这些命令的用处。JumpCommand只能 让玩家的角色跳跃。让我们放松这个限制。 不让函数去找它们控制的角色,我们将函数控制的角色对象传进去:
class Command |
这里的 GameActor 是代表游戏世界中角色的 “游戏对象” 类。 我们将其传给 execute(),这样命令类的子类就可以调用所选游戏对象上的方法,就像这样:
class JumpCommand : public Command |
现在,我们可以使用这个类让游戏中的任何角色跳来跳去了。 在输入控制部分和在对象上调用命令部分之间,我们还缺了一块代码。 第一,我们修改 handleInput(),让它可以返回命令:
Command* InputHandler::handleInput() |
这里不能立即执行,因为还不知道哪个角色会传进来。 这里我们享受了命令是具体调用的好处 —— 延迟到调用执行时再知道。
然后,需要一些接受命令的代码,作用在玩家角色上。像这样:
Command* command = inputHandler.handleInput(); |
将 actor 视为玩家角色的引用,它会正确地按着玩家的输入移动, 所以我们赋予了角色和前面例子中相同的行为。 通过在命令和角色间增加了一层重定向, 我们获得了一个灵巧的功能:我们可以让玩家控制游戏中的任何角色,只需向命令传入不同的角色。
在实践中,这个特性并不经常使用,但是经常会有类似的用例跳出来。 到目前为止,我们只考虑了玩家控制的角色,但是游戏中的其他角色呢? 它们被游戏 AI 控制。我们可以在 AI 和角色之间使用相同的命令模式;AI 代码只需生成 Command 对象。
在选择命令的 AI 和展现命令的游戏角色间解耦给了我们很大的灵活度。 我们可以对不同的角色使用不同的 AI,或者为了不同的行为而混合 AI。 想要一个更加有攻击性的对手?插入一个更加有攻击性的 AI 为其生成命令。 事实上,我们甚至可以为玩家角色加上 AI, 在展示阶段,游戏需要自动演示时,这是很有用的。
把控制角色的命令变为第一公民对象,去除直接方法调用中严厉的束缚。 将其视为命令队列,或者是命令流:
队列能为你做的更多事情,请看事件队列。

为什么我觉得需要为你画一幅 “流” 的图像?又是为什么它看上去像是管道?
一些代码(输入控制器或者 AI)产生一系列命令放入流中。 另一些代码(调度器或者角色自身)调用并消耗命令。 通过在中间加入队列,我们解耦了消费者和生产者。
如果将这些指令序列化,我们可以通过网络流传输它们。 我们可以接受玩家的输入,将其通过网络发送到另外一台机器上,然后重现之。这是网络多人游戏的基础。
撤销和重做
最后的这个例子是这种模式最广为人知的使用情况。 如果一个命令对象可以做一件事,那么它亦可以撤销这件事。 在一些策略游戏中使用撤销,这样你就可以回滚那些你不喜欢的操作。 它是创造游戏时必不可少的工具。 一个不能撤销误操作导致的错误的编辑器,肯定会让游戏设计师恨你。
这是经验之谈。
没有了命令模式,实现撤销非常困难,有了它,就是小菜一碟。 假设我们在制作单人回合制游戏,想让玩家能撤销移动,这样他们就可以集中注意力在策略上而不是猜测上。
我们已经使用了命令来抽象输入控制,所以每个玩家的举动都已经被封装其中。 举个例子,移动一个单位的代码可能如下:
class MoveUnitCommand : public Command |
注意这和前面的命令有些许不同。 在前面的例子中,我们需要从修改的角色那里抽象命令。 在这个例子中,我们将命令绑定到要移动的单位上。 这条命令的实例不是通用的 “移动某物” 命令;而是游戏回合中特殊的一次移动。
这展现了命令模式应用时的一种情形。 就像之前的例子,指令在某些情形中是可重用的对象,代表了可执行的事件。 我们早期的输入控制器将其实现为一个命令对象,然后在按键按下时调用其 execute () 方法。
这里的命令更加特殊。它们代表了特定时间点能做的特定事件。 这意味着输入控制代码可以在玩家下决定时创造一个实例。就像这样:
Command* handleInput() |
当然,在像 C++ 这样没有垃圾回收的语言中,这意味着执行命令的代码也要负责释放内存。
命令的一次性为我们很快地赢得了一个优点。 为了让指令可被取消,我们为每个类定义另一个需要实现的方法:
class Command |
undo() 方法回滚了 execute() 方法造成的游戏状态改变。 这里是添加了撤销功能后的移动命令:
class MoveUnitCommand : public Command |
注意我们为类添加了更多的状态。 当单位移动时,它忘记了它之前是什么样的。 如果我们想要撤销这个移动,我们需要记得单位之前的状态,也就是 xBefore_和 yBefore_的作用。
这看上去是备忘录模式使用的地方,它从来没有有效地工作过。 由于命令趋向于修改对象状态的一小部分,对数据其他部分的快照就是浪费内存。手动内存管理的消耗更小。
* 持久化数据结构 * 是另一个选项。 使用它,每次修改对象都返回一个新对象,保持原来的对象不变。巧妙的实现下,这些新对象与之前的对象共享数据,所以比克隆整个对象开销更小。
使用持久化数据结构,每条命令都存储了命令执行之前对象的引用,而撤销只是切换回之前的对象。
为了让玩家撤销移动,我们记录了执行的最后命令。当他们按下 control+z 时,我们调用命令的 undo() 方法。 (如果他们已经撤销了,那么就变成了 “重做”,我们会再一次执行命令。)
支持多重的撤销也不太难。 我们不单单记录最后一条指令,还要记录指令列表,然后用一个引用指向 “当前” 的那个。 当玩家执行一条命令,我们将其添加到列表,然后将代表 “当前” 的指针指向它。
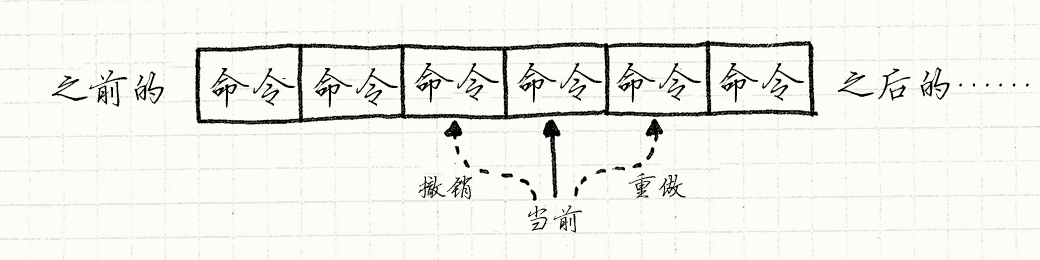
当玩家选择 “撤销”,我们撤销现在的命令,将代表当前的指针往后退。 当他们选择 “重做”,我们将代表当前的指针往前进,执行该指令。 如果在撤销后选择了新命令,那么清除命令列表中当前的指针所指命令之后的全部命令。
第一次在关卡编辑器中实现这点时,我觉得自己简直就是个天才。 我惊讶于它如此的简明有效。 你需要约束自己,保证每个数据修改都通过命令完成,一旦你做到了,余下的都很简单。
重做在游戏中并不常见,但重放常见。 一种简单的重放实现是记录游戏每帧的状态,这样它可以回放,但那会消耗太多的内存。
相反,很多游戏记录每个实体每帧运行的命令。 为了重放游戏,引擎只需要正常运行游戏,执行之前存储的命令。
用类还是用函数?
早些时候,我说过命令与第一公民函数或者闭包类似, 但是在这里展现的每个例子都是通过类完成的。 如果你更熟悉函数式编程,你也许会疑惑函数都在哪里。
我用这种方式写例子是因为 C++ 对第一公民函数支持非常有限。 函数指针没有状态,函子很奇怪而且仍然需要定义类, 在 C++11 中的 lambda 演算需要大量的人工记忆辅助才能使用。
这并不是说你在其他语言中不可以用函数来完成命令模式。 如果你使用的语言支持闭包,不管怎样,快去用它! 在某种程度上说,命令模式是为一些没有闭包的语言模拟闭包。
(我说某种程度上是因为,即使是那些支持闭包的语言, 为命令建立真正的类或者结构也是很有用的。 如果你的命令拥有多重操作(比如可撤销的命令), 将其全部映射到同一函数中并不优雅。)
定义一个有字段的真实类能帮助读者理解命令包含了什么数据。 闭包是自动包装状态的完美解决方案,但它们过于自动化而很难看清包装的真正状态有哪些。
举个例子,如果我们使用 javascript 来写游戏,那么我们可以用这种方式来写让单位移动的命令:
function makeMoveUnitCommand(unit, x, y) { |
我们可以通过一对闭包来为撤销提供支持:
function makeMoveUnitCommand(unit, x, y) { |
如果你习惯了函数式编程风格,这种做法是很自然的。 如果你没有,我希望这章可以帮你了解一些。 对于我而言,命令模式展现了函数式范式在很多问题上的高效性。
参见
- 你最终可能会得到很多不同的命令类。 为了更容易实现这些类,定义一个具体的基类,包含一些能定义行为的高层方法,往往会有帮助。 这将命令的主体
execute()转到子类沙箱中。 - 在上面的例子中,我们明确地指定哪个角色会处理命令。 在某些情况下,特别是当对象模型分层时,也可以不这么简单粗暴。 对象可以响应命令,或者将命令交给它的从属对象。 如果你这样做,你就完成了一个职责链模式。
- 有些命令是无状态的纯粹行为,比如第一个例子中的
JumpCommand。 在这种情况下,有多个实例是在浪费内存,因为所有的实例是等价的。 可以用享元模式解决。
你可以将其实现为单例,但真朋友不会让你用单例
享元模式
迷雾散尽,露出了古朴庄严的森林。古老的铁杉,在头顶编成绿色穹顶。 阳光在树叶间破碎成金色顶棚。从树干间远眺,远处的森林渐渐隐去。
这是我们游戏开发者梦想的超凡场景,这样的场景通常由一个模式支撑着,它的名字低调至极:享元模式。
森林
用几句话就能描述一片巨大的森林,但是在实时游戏中做这件事就完全是另外一件事了。 当屏幕上需要显示一整个森林时,图形程序员看到的是每秒需要送到 GPU 六十次的百万多边形。
我们讨论的是成千上万的树,每棵都由上千的多边形组成。 就算有足够的内存描述森林,渲染的过程中,CPU 到 GPU 的部分也太过繁忙了。
每棵树都有一系列与之相关的位:
- 定义树干,树枝和树叶形状的多边形网格。
- 树皮和树叶的纹理。
- 在森林中树的位置和朝向。
- 大小和色彩之类的调节参数,让每棵树都看起来与众不同。
如果用代码表示,那么会得到这样的东西:
class Tree |
这是一大堆数据,多边形网格和纹理体积非常大。 描述整个森林的对象在一帧的时间就交给 GPU 实在是太过了。 幸运的是,有一种老办法来处理它。
关键点在于,哪怕森林里有千千万万的树,它们大多数长得一模一样。 它们使用了相同的网格和纹理。 这意味着这些树的实例的大部分字段是一样的。
你要么是疯了,要么是亿万富翁,才能让美术给森林里每棵树建立独立模型。

注意每一棵树的小盒子中的东西都是一样的。
我们可以通过显式地将对象切为两部分来更加明确地模拟。 第一,将树共有的数据拿出来分离到另一个类中:
class TreeModel |
游戏只需要一个这种类, 因为没有必要在内存中把相同的网格和纹理重复一千遍。 游戏世界中每个树的实例只需有一个对这个共享 TreeModel 的引用。 留在 Tree 中的是那些实例相关的数据:
class Tree |
你可以将其想象成这样:

这有点像类型对象模式。 两者都涉及将一个类中的状态委托给另外的类,来达到在不同实例间分享状态的目的。 但是,这两种模式背后的意图不同。
使用类型对象,目标是通过将类型引入对象模型,减少需要定义的类。 伴随而来的内容分享是额外的好处。享元模式则是纯粹的为了效率。
把所有的东西都存在主存里没什么问题,但是这对渲染也毫无帮助。 在森林到屏幕上之前,它得先到 GPU。我们需要用显卡可以识别的方式共享数据。
一千个实例
为了减少需要推送到 GPU 的数据量,我们想把共享的数据 ——TreeModel—— 只发送一次。 然后,我们分别发送每个树独特的数据 —— 位置,颜色,大小。 最后,我们告诉 GPU,“使用同一模型渲染每个实例”。
幸运的是,今日的图形接口和显卡正好支持这一点。 这些细节很繁琐且超出了这部书的范围,但是 Direct3D 和 OpenGL 都可以做实例渲染。
在这些 API 中,你需要提供两部分数据流。 第一部分是一块需要渲染多次的共同数据 —— 在例子中是树的网格和纹理。 第二部分是实例的列表以及绘制第一部分时需要使用的参数。 然后调用一次渲染,绘制整个森林。
这个 API 是由显卡直接实现的,意味着享元模式也许是唯一的有硬件支持的 GoF 设计模式。
享元模式
好了,我们已经看了一个具体的例子,下面我介绍模式的通用部分。 享元,就像它的名字暗示的那样, 当你需要共享类时使用,通常是因为你有太多这种类了。
实例渲染时,每棵树通过总线送到 GPU 消耗的更多是时间而非内存,但是基本要点是一样的。
这个模式通过将对象的数据分为两种来解决这个问题。 第一种数据没有特定指明是哪个对象的实例,因此可以在它们间分享。 Gof 称之为固有状态,但是我更喜欢将其视为 “上下文无关” 部分。 在这里的例子中,是树的网格和纹理。
数据的剩余部分是变化状态,那些每个实例独一无二的东西。 在这个例子中,是每棵树的位置,拉伸和颜色。 就像这里的示例代码块一样,这种模式通过在每个对象出现时共享一份固有状态来节约内存。
就目前而言,这看上去像是基础的资源共享,很难被称为一种模式。 部分原因是在这个例子中,我们可以为共享状态划出一个清晰的身份:TreeModel。
我发现,当共享对象没有有效定义的实体时,使用这种模式就不那么明显(使用它也就越发显得精明)。 在那些情况下,这看上去是一个对象被魔术般地同时分配到了多个地方。 让我展示给你另外一个例子。
扎根之所
这些树长出来的地方也需要在游戏中表示。 这里可能有草,泥土,丘陵,湖泊,河流,以及其它任何你可以想到的地形。 我们基于区块建立地表:世界的表面被划分为由微小区块组成的巨大网格。 每个区块都由一种地形覆盖。
每种地形类型都有一系列特性会影响游戏玩法:
- 决定了玩家能够多快地穿过它的移动开销。
- 表明能否用船穿过的水域标识。
- 用来渲染它的纹理。
因为我们游戏程序员偏执于效率,我们不会在每个区块中保存这些状态。 相反,一个通用的方式是为每种地形使用一个枚举。
再怎么样,我们也已经从树的例子吸取教训了。
enum Terrain |
然后,世界管理巨大的网格:
class World |
这里我使用嵌套数组存储 2D 网格。 在 C/C++ 中这样是很有效率的,因为它会将所有元素打包在一起。 在 Java 或者其他内存管理语言中,那样做会实际给你一个数组,其中每个元素都是对数组的列的引用,那就不像你想要的那样内存友好了。
反正,隐藏 2D 网格数据结构背后的实现细节,能使代码更好地工作。 我这里这样做只是为了让其保持简单。
为了获得区块的实际有用的数据,我们做了一些这样的事情:
int World::getMovementCost(int x, int y) |
你知道我的意思了。这可行,但是我觉得很丑。 移动开销和水域标识是区块的数据,但在这里它们散布在代码中。 更糟的是,简单地形的数据被众多方法拆开了。 如果能够将这些包裹起来就好了。毕竟,那是我们设计对象的目的。
如果我们有实际的地形类就好了,像这样:
class Terrain |
你会注意这里所有的方法都是
const。这不是巧合。 由于同一对象在多处引用,如果你修改了它, 改变会同时在多个地方出现。这也许不是你想要的。 通过分享对象来节约内存的这种优化,不应该影响到应用的显性行为。 因此,享元对象几乎总是不可变的。
但是我们不想为每个区块都保存一个实例。 如果你看看这个类内部,你会发现里面实际上什么也没有, 唯一特别的是区块在哪里。 用享元的术语讲,区块的所有状态都是 “固有的” 或者说 “上下文无关的”。
鉴于此,我们没有必要保存多个同种地形类型。 地面上的草区块两两无异。 我们不用地形区块对象枚举构成世界网格,而是用 Terrain 对象指针组成网格:
class World |
每个相同地形的区块会指向相同的地形实例。
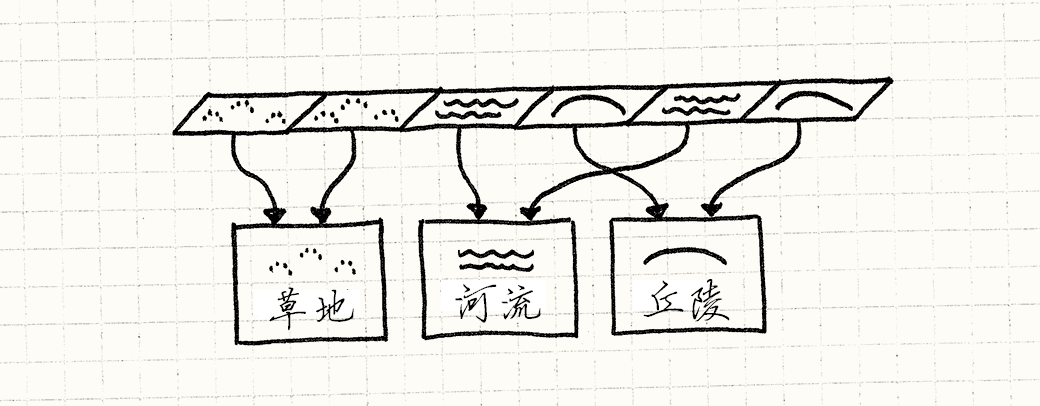
由于地形实例在很多地方使用,如果你想要动态分配,它们的生命周期会有点复杂。 因此,我们直接在游戏世界中存储它们。
class World |
然后我们可以像这样来描绘地面:
void World::generateTerrain() |
我承认这不是世界上最好的地形生成算法。
现在不需要 World 中的方法来接触地形属性,我们可以直接暴露出 Terrain 对象。
const Terrain& World::getTile(int x, int y) const |
用这种方式,World 不再与各种地形的细节耦合。 如果你想要某一区块的属性,可直接从那个对象获得:
int cost = world.getTile(2, 3).getMovementCost(); |
我们回到了操作实体对象的 API,几乎没有额外开销 —— 指针通常不比枚举大。
性能如何?
我在这里说几乎,是因为性能偏执狂肯定会想要知道它和枚举比起来如何。 通过解引用指针获取地形需要一次间接跳转。 为了获得移动开销这样的地形数据,你首先需要跟着网格中的指针找到地形对象, 然后再找到移动开销。跟踪这样的指针会导致缓存不命中,降低运行速度。
需要更多指针追逐和缓存不命中的相关信息,看看数据局部性这章。
就像往常一样,优化的金科玉律是需求优先。 现代计算机硬件过于复杂,性能只是游戏的一个考虑方面。 在我这章做的测试中,享元较枚举没有什么性能上的损失。 享元实际上明显更快。但是这完全取决于内存中的事物是如何排列的。
我可以自信地说使用享元对象不会搞到不可收拾。 它给了你面向对象的优势,而且没有产生一堆对象。 如果你创建了一个枚举,又在它上面做了很多分支跳转,考虑一下这个模式吧。 如果你担心性能,那么至少在把代码编程为难以维护的风格之前先做些性能分析。
参见
在区块的例子中,我们只是为每种地形创建一个实例然后存储在
World中。 这也许能更好找到和重用这些实例。 但是在多数情况下,你不会在一开始就创建所有享元。如果你不能预料哪些是实际上需要的,最好在需要时才创建。 为了保持共享的优势,当你需要一个时,首先看看是否已经创建了一个相同的实例。 如果确实如此,那么只需返回那个实例。
这通常意味需要将构造函数封装在查询对象是否存在的接口之后。 像这样隐藏构造指令是工厂方法的一个例子。
为了返回一个早先创建的享元,需要追踪那些已经实例化的对象池。 正如其名,这意味着对象池是存储它们的好地方。
当使用状态模式时, 经常会出现一些没有任何特定字段的 “状态对象”。 这个状态的标识和方法都很有用。 在这种情况下,你可以使用这个模式,然后在不同的状态机上使用相同的对象实例。
观察者模式
随便打开电脑中的一个应用,很有可能它就使用了 MVC 架构, 而究其根本,是因为观察者模式。 观察者模式应用广泛,Java 甚至将其放到了核心库之中(java.util.Observer),而 C# 直接将其嵌入了语法(event关键字)。
就像软件中的很多东西,MVC 是 Smalltalkers 在七十年代创造的。 Lisp 程序员也许会说其实是他们在六十年代发明的,但是他们懒得记下来。
观察者模式是应用最广泛和最广为人知的 GoF 模式,但是游戏开发世界与世隔绝, 所以对你来说,它也许是全新的。 假设你与世隔绝,让我给你举个形象的例子。
成就解锁
假设我们向游戏中添加了成就系统。 它存储了玩家可以完成的各种各样的成就,比如 “杀死 1000 只猴子恶魔”,“从桥上掉下去”,或者 “一命通关”。

我发誓画的这个没有第二个意思,笑。
要实现这样一个包含各种行为来解锁成就的系统是很有技巧的。 如果我们不够小心,成就系统会缠绕在代码库的每个黑暗角落。 当然,“从桥上掉落” 和物理引擎相关, 但我们并不想看到在处理撞击代码的线性代数时, 有个对 unlockFallOffBridge() 的调用是不?
这只是随口一说。 有自尊的物理程序员绝不会允许像游戏玩法这样的平凡之物玷污他们优美的算式。
我们喜欢的是,照旧,让关注游戏一部分的所有代码集成到一块。 挑战在于,成就在游戏的不同层面被触发。怎么解耦成就系统和其他部分呢?
这就是观察者模式出现的原因。 这让代码宣称有趣的事情发生了,而不必关心到底是谁接受了通知。
举个例子,有物理代码处理重力,追踪哪些物体待在地表,哪些坠入深渊。 为了实现 “桥上掉落” 的徽章,我们可以直接把成就代码放在那里,但那就会一团糟。 相反,可以这样做:
void Physics::updateEntity(Entity& entity) |
它做的就是声称,“额,我不知道有谁感兴趣,但是这个东西刚刚掉下去了。做你想做的事吧。”
物理引擎确实决定了要发送什么通知,所以这并没有完全解耦。但在架构这个领域,通常只能让系统变得更好,而不是完美。
成就系统注册它自己为观察者,这样无论何时物理代码发送通知,成就系统都能收到。 它可以检查掉落的物体是不是我们的失足英雄, 他之前有没有做过这种不愉快的与桥的经典力学遭遇。 如果满足条件,就伴着礼花和炫光解锁合适的成就,而这些都无需牵扯到物理代码。
事实上,我们可以改变成就的集合或者删除整个成就系统,而不必修改物理引擎。 它仍然会发送它的通知,哪怕实际没有东西接收。
当然,如果我们永久移除成就,没有任何东西需要物理引擎的通知, 我们也同样可以移除通知代码。但是在游戏的演进中,最好保持这里的灵活性。
它如何运作
如果你还不知道如何实现这个模式,你可能可以从之前的描述中猜到,但是为了减轻你的负担,我还是过一遍代码吧。
观察者
我们从那个需要知道别的对象做了什么事的类开始。 这些好打听的对象用如下接口定义:
class Observer |
onNotify()的参数取决于你。这就是为什么是观察者模式, 而不是 “可以粘贴到游戏中的真实代码”。 典型的参数是发送通知的对象和一个装入其他细节的 “数据” 参数。如果你用泛型或者模板编程,你可能会在这里使用它们,但是根据你的特殊用况裁剪它们也很好。 这里,我将其硬编码为接受一个游戏实体和一个描述发生了什么的枚举。
任何实现了这个的具体类就成为了观察者。 在我们的例子中,是成就系统,所以我们可以像这样实现:
class Achievements : public Observer |
被观察者
被观察的对象拥有通知的方法函数,用 GoF 的说法,那些对象被称为 “主题”。 它有两个任务。首先,它有一个列表,保存默默等它通知的观察者:
class Subject |
在真实代码中,你会使用动态大小的集合而不是一个定长数组。 在这里,我使用这种最基础的形式是为了那些不了解 C++ 标准库的人们。
重点是被观察者暴露了公开的 API 来修改这个列表:
class Subject |
这就允许了外界代码控制谁接收通知。 被观察者与观察者交流,但是不与它们耦合。 在我们的例子中,没有一行物理代码会提及成就。 但它仍然可以与成就系统交流。这就是这个模式的聪慧之处。
被观察者有一列表观察者而不是单个观察者也是很重要的。 这保证了观察者不会相互干扰。 举个例子,假设音频引擎也需要观察坠落事件来播放合适的音乐。 如果客体只支持单个观察者,当音频引擎注册时,就会取消成就系统的注册。
这意味着这两个系统需要相互交互 —— 而且是用一种极其糟糕的方式, 第二个注册时会使第一个的注册失效。 支持一列表的观察者保证了每个观察者都是被独立处理的。 就它们各自的视角来看,自己是这世界上唯一看着被观察者的。
被观察者的剩余任务就是发送通知:
class Subject |
注意,代码假设了观察者不会在它们的
onNotify()方法中修改观察者列表。 更加可靠的实现方法会阻止或优雅地处理这样的并发修改。
可被观察的物理系统
现在,我们只需要给物理引擎和这些挂钩,这样它可以发送消息, 成就系统可以和引擎连线来接受消息。 我们按照传统的设计模式方法实现,继承 Subject:
class Physics : public Subject |
这让我们将 notify() 实现为了 Subject 内的保护方法。 这样派生的物理引擎类可以调用并发送通知,但是外部的代码不行。 同时,addObserver() 和 removeObserver() 是公开的, 所以任何可以接触物理引擎的东西都可以观察它。
在真实代码中,我会避免使用这里的继承。 相反,我会让
Physics有 一个Subject的实例。 不再是观察物理引擎本身,被观察的会是独立的 “下落事件” 对象。 观察者可以用像这样注册它们自己:
.addObserver(this);对我而言,这是 “观察者” 系统与 “事件” 系统的不同之处。 使用前者,你观察做了有趣事情的事物。 使用后者,你观察的对象代表了发生的有趣事情。
现在,当物理引擎做了些值得关注的事情,它调用 notify(),就像之前的例子。 它遍历了观察者列表,通知所有观察者。

很简单,对吧?只要一个类管理一列表指向接口实例的指针。 难以置信的是,如此直观的东西是无数程序和应用框架交流的主心骨。
观察者模式不是完美无缺的。当我问其他程序员怎么看,他们提出了一些抱怨。 让我们看看可以做些什么来处理这些抱怨。
太慢了
我经常听到这点,通常是从那些不知道模式具体细节的程序员那里。 他们有一种假设,任何东西只要沾到了 “设计模式”,那么一定包含了一堆类,跳转和浪费 CPU 循环其他行为。
观察者模式的名声特别坏,一些坏名声的事物与它如影随形, 比如 “事件”,“消息”,甚至 “数据绑定”。 其中的一些系统确实会慢。(通常是故意的,出于好的意图)。 他们使用队列,或者为每个通知动态分配内存。
这就是为什么我认为设计模式文档化很重要。 当我们没有统一的术语,我们就失去了简洁明确表达的能力。 你说 “观察者”,我以为是 “事件”,他以为是 “消息”, 因为没人花时间记下差异,也没人阅读。
而那就是在这本书中我要做的。 本书中也有一章关于事件和消息:事件队列.
现在你看到了模式是如何真正被实现的, 你知道事实并不如他们所想的这样。 发送通知只需简单地遍历列表,调用一些虚方法。 是的,这比静态调用慢一点,除非是性能攸关的代码,否则这点消耗都是微不足道的。
我发现这个模式在代码性能瓶颈以外的地方能有很好的应用, 那些你可以承担动态分配消耗的地方。 除那以外,使用它几乎毫无限制。 我们不必为消息分配对象,也无需使用队列。这里只多了一个用在同步方法调用上的额外跳转。
太快?
事实上,你得小心,观察者模式是同步的。 被观察者直接调用了观察者,这意味着直到所有观察者的通知方法返回后, 被观察者才会继续自己的工作。观察者会阻塞被观察者的运行。
这听起来很疯狂,但在实践中,这可不是世界末日。 这只是值得注意的事情。 UI 程序员 —— 那些使用基于事件的编程的程序员已经这么干了很多年了 —— 有句经典名言:“远离 UI 线程”。
如果要对事件同步响应,你需要完成响应,尽可能快地返回,这样 UI 就不会锁死。 当你有耗时的操作要执行时,将这些操作推到另一个线程或工作队列中去。
你需要小心地在观察者中混合线程和锁。 如果观察者试图获得被观察者拥有的锁,游戏就进入死锁了。 在多线程引擎中,你最好使用事件队列来做异步通信。
“它做了太多动态分配”
整个程序员社区 —— 包括很多游戏开发者 —— 转向了拥有垃圾回收机制的语言, 动态分配今昔非比。 但在像游戏这样性能攸关的软件中,哪怕是在有垃圾回收机制的语言,内存分配也依然重要。 动态分配需要时间,回收内存也需要时间,哪怕是自动运行的。
很多游戏开发者不怎么担心分配,但很担心分页。 当游戏需要不崩溃地连续运行多日来获得发售资格,不断增加的分页堆会影响游戏的发售。
对象池模式一章介绍了避免这点的常用技术,以及更多其他细节。
在上面的示例代码中,我使用的是定长数组,因为我想尽可能保证简单。 在真实的项目中中,观察者列表随着观察者的添加和删除而动态地增长和缩短。 这种内存的分配吓坏了一些人。
当然,第一件需要注意的事情是只在观察者加入时分配内存。 发送通知无需内存分配 —— 只需一个方法调用。 如果你在游戏一开始就加入观察者而不乱动它们,分配的总量是很小的。
如果这仍然困扰你,我会介绍一种无需任何动态分配的方式来增加和删除观察者。
链式观察者
我们现在看到的所有代码中,Subject 拥有一列指针指向观察它的 Observer。 Observer 类本身没有对这个列表的引用。 它是纯粹的虚接口。优先使用接口,而不是有状态的具体类,这大体上是一件好事。
但是如果我们确实愿意在 Observer 中放一些状态, 我们可以将观察者的列表分布到观察者自己中来解决动态分配问题。 不是被观察者保留一列表分散的指针,观察者对象本身成为了链表中的一部分:

为了实现这一点,我们首先要摆脱 Subject 中的数组,然后用链表头部的指针取而代之:
class Subject |
然后,我们在 Observer 中添加指向链表中下一观察者的指针。
class Observer |
这里我们也让 Subject 成为了友类。 被观察者拥有增删观察者的 API,但是现在链表在 Observer 内部管理。 最简单的实现办法就是让被观察者类成为友类。
注册一个新观察者就是将其连到链表中。我们用更简单的实现方法,将其插到开头:
void Subject::addObserver(Observer* observer) |
另一个选项是将其添加到链表的末尾。这么做增加了一定的复杂性。 Subject 要么遍历整个链表来找到尾部,要么保留一个单独 tail_指针指向最后一个节点。
加在在列表的头部很简单,但也有另一副作用。 当我们遍历列表给每个观察者发送一个通知, 最新注册的观察者最先接到通知。 所以如果以 A,B,C 的顺序来注册观察者,它们会以 C,B,A 的顺序接到通知。
理论上,这种还是那种方式没什么差别。 在好的观察者设计中,观察同一被观察者的两个观察者互相之间不该有任何顺序相关。 如果顺序确实有影响,这意味着这两个观察者有一些微妙的耦合,最终会害了你。
让我们完成删除操作:
void Subject::removeObserver(Observer* observer) |
如你所见,从链表移除一个节点通常需要处理一些丑陋的特殊情况,应对头节点。 还可以使用指针的指针,实现一个更优雅的方案。
我在这里没有那么做,是因为半数看到这个方案的人都迷糊了。 但这是一个很值得做的练习:它能帮助你深入思考指针。
因为使用的是链表,所以我们得遍历它才能找到要删除的观察者。 如果我们使用普通的数组,也得做相同的事。 如果我们使用双向链表,每个观察者都有指向前面和后面的指针, 就可以用常量时间移除观察者。在实际项目中,我会这样做。
剩下的事情只有发送通知了,这和遍历列表同样简单;
void Subject::notify(const Entity& entity, Event event) |
这里,我们遍历了整个链表,通知了其中每一个观察者。 这保证了所有的观察者相互独立并有同样的优先级。
我们可以这样实现,当观察者接到通知,它返回了一个标识,表明被观察者是否应该继续遍历列表。 如果这样做,你就接近了职责链模式。
不差嘛,对吧?被观察者现在想有多少观察者就有多少观察者,无需动态内存。 注册和取消注册就像使用简单数组一样快。 但是,我们牺牲了一些小小的功能特性。
由于我们使用观察者对象作为链表节点,这暗示它只能存在于一个观察者链表中。 换言之,一个观察者一次只能观察一个被观察者。 在传统的实现中,每个被观察者有独立的列表,一个观察者同时可以存在于多个列表中。
你也许可以接受这一限制。 通常是一个被观察者有多个观察者,反过来就很少见了。 如果这真是一个问题,这里还有一种不必使用动态分配的解决方案。 详细介绍的话,这章就太长了,但我会大致描述一下,其余的你可以自行填补……
链表节点池
就像之前,每个被观察者有一链表的观察者。 但是,这些链表节点不是观察者本身。 相反,它们是分散的小 “链表节点” 对象, 包含了指向观察者的指针和指向链表下一节点的指针。

由于多个节点可以指向同一观察者,这就意味着观察者可以同时在超过多个被观察者的列表中。 我们可以同时观察多个对象了。
链表有两种风格。学校教授的那种,节点对象包含数据。 在我们之前的观察者链表的例子中,是另一种: 数据(这个例子中是观察者)包含了节点(
next_指针)。后者的风格被称为 “侵入式” 链表,因为在对象内部使用链表侵入了对象本身的定义。 侵入式链表灵活性更小,但如我们所见,也更有效率。 在 Linux 核心这样的地方这种风格很流行。
避免动态分配的方法很简单:由于这些节点都是同样大小和类型, 可以预先在对象池中分配它们。 这样你只需处理固定大小的列表节点,可以随你所需使用和重用, 而无需牵扯到真正的内存分配器。
剩余的问题
我认为该模式将人们吓阻的三个主要问题已经被搞定了。 它简单,快速,对内存管理友好。 但是这意味着你总该使用观察者吗?
现在,这是另一个的问题。 就像所有的设计模式,观察者模式不是万能药。 哪怕可以正确高效地的实现,它也不一定是好的解决方案。 设计模式声名狼藉的原因之一就是人们将好模式用在错误的问题上,得到了糟糕的结果。
还有两个挑战,一个是关于技术,另一个更偏向于可维护性。 我们先处理关于技术的挑战,因为关于技术的问题总是更容易处理。
销毁被观察者和观察者
我们看到的样例代码健壮可用,但有一个严重的副作用: 当删除一个被观察者或观察者时会发生什么? 如果你不小心在某些观察者上面调用了 delete,被观察者也许仍然持有指向它的指针。 那是一个指向一片已释放区域的悬空指针。 当被观察者试图发送一个通知,额…… 就说发生的事情会出乎你的意料之外吧。
不是谴责,但我注意到设计模式完全没提这个问题。
删除被观察者更容易些,因为在大多数实现中,观察者没有对它的引用。 但是即使这样,将被观察者所占的字节直接回收可能还是会造成一些问题。 这些观察者也许仍然期待在以后收到通知,而这是不可能的了。 它们没法继续观察了,真的,它们只是认为它们可以。
你可以用好几种方式处理这点。 最简单的就是像我做的那样,以后一脚踩空。 在被删除时取消注册是观察者的职责。 多数情况下,观察者确实知道它在观察哪个被观察者, 所以通常需要做的只是给它的析构器添加一个 removeObserver()。
通常在这种情况下,难点不在如何做,而在记得做。
如果在删除被观察者时,你不想让观察者处理问题,这也很好解决。 只需要让被观察者在它被删除前发送一个最终的 “死亡通知”。 这样,任何观察者都可以接收到,然后做些合适的行为。
默哀,献花,挽歌……
人 —— 哪怕是那些花费在大量时间在机器前,拥有让我们黯然失色的才能的人 —— 也是绝对不可靠的。 这就是为什么我们发明了电脑:它们不像我们那样经常犯错误。
更安全的方案是在每个被观察者销毁时,让观察者自动取消注册。 如果你在观察者基类中实现了这个逻辑,每个人不必记住就可以使用它。 这确实增加了一定的复杂度。 这意味着每个观察者都需要有它在观察的被观察者的列表。 最终维护一个双向指针。
别担心,我有垃圾回收器
你们那些装备有垃圾回收系统的孩子现在一定很洋洋自得。 觉得你不必担心这个,因为你从来不必显式删除任何东西?再仔细想想!
想象一下:你有 UI 显示玩家角色情况的状态,比如健康和道具。 当玩家在屏幕上时,你为其初始化了一个对象。 当 UI 退出时,你直接忘掉这个对象,交给 GC 清理。
每当角色脸上(或者其他什么地方)挨了一拳,就发送一个通知。 UI 观察到了,然后更新健康槽。很好。 当玩家离开场景,但你没有取消观察者的注册,会发生什么?
UI 界面不再可见,但也不会进入垃圾回收系统,因为角色的观察者列表还保存着对它的引用。 每一次场景加载后,我们给那个不断增长的观察者列表添加一个新实例。
玩家玩游戏时,来回跑动,打架,角色的通知发送给所有的界面。 它们不在屏幕上,但它们接受通知,这样就浪费 CPU 循环在不可见的 UI 元素上了。 如果它们会播放声音之类的,这样的错误就会被人察觉。
这在通知系统中非常常见,甚至专门有个名字:失效监听者问题。 由于被观察者保留了对观察者的引用,最终有 UI 界面对象僵死在内存中。 这里的教训是要及时删除观察者。
它甚至有专门的维基条目。
然后呢?
观察者的另一个深层次问题是它的意图直接导致的。 我们使用它是因为它帮助我们放松了两块代码之间的耦合。 它让被观察者与没有静态绑定的观察者间接交流。
当你要理解被观察者的行为时,这很有价值,任何不相关的事情都是在分散注意力。 如果你在处理物理引擎,你根本不想要编辑器 —— 或者你的大脑 —— 被一堆成就系统的东西而搞糊涂。
另一方面,如果你的程序没能运行,漏洞散布在多个观察者之间,理清信息流变得更加困难。 显式耦合中更易于查看哪一个方法被调用了。 这是因为耦合是静态的,IDE 分析它轻而易举。
但是如果耦合发生在观察者列表中,想要知道哪个观察者被通知到了,唯一的办法是看看哪个观察者在列表中,而且处于运行中。 你得理清它的命令式,动态行为而非理清程序的静态交流结构。
处理这个的指导原则很简单。 如果为了理解程序的一部分,两个交流的模块都需要考虑, 那就不要使用观察者模式,使用其他更加显式的东西。
当你在某些大型程序上用黑魔法时,你会感觉这样处理很笨拙。 我们有很多术语用来描述,比如 “关注点分离”,“一致性和内聚性” 和 “模块化”, 总归就是 “这些东西待在一起,而不是与那些东西待在一起。”
观察者模式是一个让这些不相关的代码块互相交流,而不必打包成更大的块的好方法。 这在专注于一个特性或层面的单一代码块内不会太有用。
这就是为什么它能很好地适应我们的例子: 成就和物理是几乎完全不相干的领域,通常被不同的人实现。 我们想要它们之间的交流最小化, 这样无论在哪一个上工作都不需要另一个的太多信息。
今日观察者
设计模式源于 1994。 那时候,面向对象语言正是热门的编程范式。 每个程序员都想要 “30 天学会面向对象编程”, 中层管理员根据程序员创建类的数量为他们支付工资。 工程师通过继承层次的深度评价代码质量。
同一年,Ace of Base 的畅销单曲发行了三首而不是一首,这也许能让你了解一些我们那时的品味和洞察力。
观察者模式在那个时代中很流行,所以构建它需要很多类就不奇怪了。 但是现代的主流程序员更加适应函数式语言。 实现一整套接口只是为了接受一个通知不再符合今日的美学了。
它看上去是又沉重又死板。它确实又沉重又死板。 举个例子,在观察者类中,你不能为不同的被观察者调用不同的通知方法。
这就是为什么被观察者经常将自身传给观察者。 观察者只有单一的
onNotify()方法, 如果它观察多个被观察者,它需要知道哪个被观察者在调用它的方法。
现代的解决办法是让 “观察者” 只是对方法或者函数的引用。 在函数作为第一公民的语言中,特别是那些有闭包的, 这种实现观察者的方式更为普遍。
今日,几乎每种语言都有闭包。C++ 克服了在没有垃圾回收的语言中构建闭包的挑战, 甚至 Java 都在 JDK8 中引入了闭包。
举个例子,C# 有 “事件” 嵌在语言中。 通过这样,观察者是一个 “委托”, (“委托” 是方法的引用在 C# 中的术语)。 在 JavaScript 事件系统中,观察者可以是支持了特定 EventListener 协议的类, 但是它们也可以是函数。 后者是人们常用的方式。
如果设计今日的观察者模式,我会让它基于函数而不是基于类。 哪怕是在 C++ 中,我倾向于让你注册一个成员函数指针作为观察者,而不是 Observer 接口的实例。
这里的一篇有趣博文以某种方式在 C++ 上实现了这一点。
明日观察者
事件系统和其他类似观察者的模式如今遍地都是。 它们都是成熟的方案。 但是如果你用它们写一个稍微大一些的应用,你会发现一件事情。 在观察者中很多代码最后都长得一样。通常是这样:
1. 获知有状态改变了。 |
就是这样,“哦,英雄的健康现在是 7 了?让我们把血条的宽度设为 70 像素。 过上一段时间,这会变得很沉闷。 计算机科学学术界和软件工程师已经用了很长时间尝试结束这种状况了。 这些方式被赋予了不同的名字:“数据流编程”,“函数反射编程” 等等。
即使有所突破,一般也局限在特定的领域中,比如音频处理或芯片设计,我们还没有找到万能钥匙。 与此同时,一个更脚踏实地的方式开始获得成效。那就是现在的很多应用框架使用的 “数据绑定”。
不像激进的方式,数据绑定不再指望完全终结命令式代码, 也不尝试基于巨大的声明式数据图表架构整个应用。 它做的只是自动改变 UI 元素或计算某些数值来反映一些值的变化。
就像其他声明式系统,数据绑定也许太慢,嵌入游戏引擎的核心也太复杂。 但是如果说它不会侵入游戏不那么性能攸关的部分,比如 UI,那我会很惊讶。
与此同时,经典观察者模式仍然在那里等着我们。 是的,它不像其他的新热门技术一样在名字中填满了 “函数”“反射”, 但是它超简单而且能正常工作。对我而言,这通常是解决方案最重要的条件。
原型模式
我第一次听到 “原型” 这个词是在设计模式中。 如今,似乎每个人都在用这个词,但他们讨论的实际上不是设计模式。 我们会讨论他们所说的原型,也会讨论术语 “原型” 的有趣之处,和其背后的理念。 但首先,让我们重访传统的设计模式。
“传统的” 一词可不是随便用的。 设计模式引自 1963 年 Ivan Sutherland 的 Sketchpad 传奇项目,那是这个模式首次出现。 当其他人在听迪伦和甲壳虫乐队时,Sutherland 正忙于,你知道的,发明 CAD,交互图形和面向对象编程的基本概念。
看看这个 demo,跪服吧。
原型设计模式
假设我们要用《圣铠传说》的风格做款游戏。 野兽和恶魔围绕着英雄,争着要吃他的血肉。 这些可怖的同行者通过 “生产者” 进入这片区域,每种敌人有不同的生产者。
在这个例子中,假设我们游戏中每种怪物都有不同的类 ——Ghost,Demon,Sorcerer 等等,像这样:
class Monster |
生产者构造特定种类怪物的实例。 为了在游戏中支持每种怪物,我们可以用一种暴力的实现方法, 让每个怪物类都有生产者类,得到平行的类结构:

我得翻出落满灰尘的 UML 书来画这个图表。
代表 “继承”。
实现后看起来像是这样:
class Spawner |
除非你会根据代码量来获得工资, 否则将这些焊在一起很明显不是好方法。 众多类,众多引用,众多冗余,众多副本,众多重复自我……
原型模式提供了一个解决方案。 关键思路是一个对象可以产出与它自己相近的对象。 如果你有一个恶灵,你可以制造更多恶灵。 如果你有一个恶魔,你可以制造其他恶魔。 任何怪物都可以被视为原型怪物,产出其他版本的自己。
为了实现这个功能,我们给基类 Monster 添加一个抽象方法 clone():
class Monster |
每个怪兽子类提供一个特定实现,返回与它自己的类和状态都完全一样的新对象。举个例子:
class Ghost : public Monster { |
一旦我们所有的怪物都支持这个, 我们不再需要为每个怪物类创建生产者类。我们只需定义一个类:
class Spawner |
它内部存有一个怪物,一个隐藏的怪物, 它唯一的任务就是被生产者当做模板,去产生更多一样的怪物, 有点像一个从来不离开巢穴的蜂后。
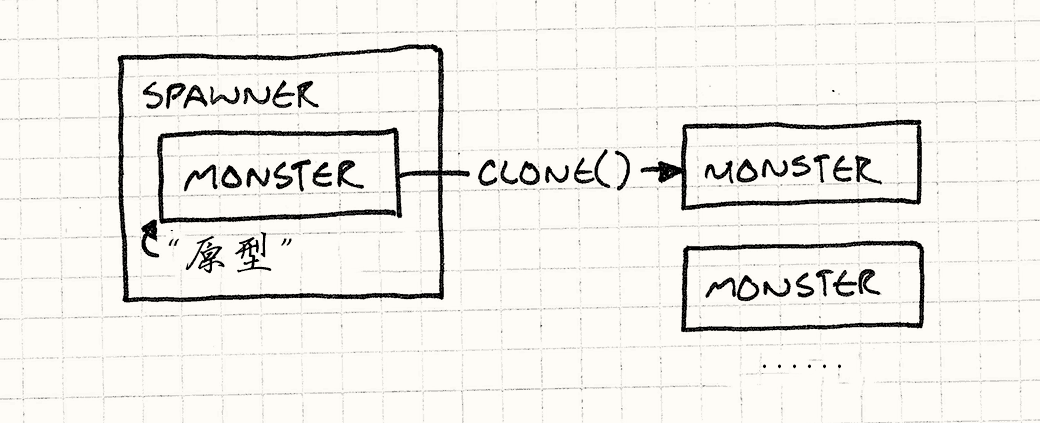
为了得到恶灵生产者,我们创建一个恶灵的原型实例,然后创建拥有这个实例的生产者:
Monster* ghostPrototype = new Ghost(15, 3); |
这个模式的灵巧之处在于它不但拷贝原型的类,也拷贝它的状态。 这就意味着我们可以创建一个生产者,生产快速鬼魂,虚弱鬼魂,慢速鬼魂,而只需创建一个合适的原型鬼魂。
我在这个模式中找到了一些既优雅又令人惊叹的东西。 我无法想象自己是如何创造出它们的,但我更无法想象不知道这些东西的自己该如何是好。
效果如何?
好吧,我们不需要为每个怪物创建单独的生产者类,那很好。 但我们确实需要在每个怪物类中实现 clone()。 这和使用生产者方法比起来也没节约多少代码量。
当你坐下来试着写一个正确的 clone(),会遇见令人不快的语义漏洞。 做深层拷贝还是浅层拷贝呢?换言之,如果恶魔拿着叉子,克隆恶魔也要克隆叉子吗?
同时,这看上去没减少已存问题上的代码, 事实上还增添了些人为的问题。 我们需要将每个怪物有独立的类作为前提条件。 这绝对不是当今大多数游戏引擎运作的方法。
我们中大部分痛苦地学到,这样庞杂的类层次管理起来很痛苦, 那就是我们为什么用组件模式和类型对象为不同的实体建模,这样无需一一建构自己的类。
生产函数
哪怕我们确实需要为每个怪物构建不同的类,这里还有其他的实现方法。 不是使用为每个怪物建立分离的生产者类,我们可以创建生产函数,就像这样:
Monster* spawnGhost() |
这比构建怪兽生产者类更简洁。生产者类只需简单地存储一个函数指针:
typedef Monster* (*SpawnCallback)(); |
为了给恶灵构建生产者,你需要做:
Spawner* ghostSpawner = new Spawner(spawnGhost); |
模板
如今,大多数 C++ 开发者已然熟悉模板了。 生产者类需要为某类怪物构建实例,但是我们不想硬编码是哪类怪物。 自然的解决方案是将它作为模板中的类型参数:
我不太确定程序员是学着喜欢 C++ 模板还是完全畏惧并远离了 C++。 不管怎样,今日我见到的程序员中,使用 C++ 的也都会使用模板。
这里的
Spawner类不必考虑将生产什么样的怪物, 它总与指向Monster的指针打交道。如果我们只有
SpawnerFor<T>类,模板类型没有办法共享父模板, 这样的话,如果一段代码需要与产生多种怪物类型的生产者打交道,就都得接受模板参数。
class Spawner |
像这样使用它:
Spawner* ghostSpawner = new SpawnerFor<Ghost>(); |
第一公民类型
前面的两个解决方案使用类完成了需求,Spawner 使用类型进行参数化。 在 C++ 中,类型不是第一公民,所以需要一些改动。 如果你使用 JavaScript,Python,或者 Ruby 这样的动态类型语言, 它们的类是可以传递的对象,你可以用更直接的办法解决这个问题。
某种程度上, 类型对象也是为了弥补第一公民类型的缺失。 但那个模式在拥有第一公民类型的语言中也有用,因为它让你决定什么是 “类型”。 你也许想要与语言内建的类不同的语义。
当你完成一个生产者,直接向它传递要构建的怪物类 —— 那个代表了怪物类的运行时对象。超容易的,对吧。
综上所述,老实说,我不能说找到了一种情景,而在这个情景下,原型设计模式是最好的方案。 也许你的体验有所不同,但现在把它搁到一边,我们讨论点别的:将原型作为一种语言范式。
原型语言范式
很多人认为 “面向对象编程” 和 “类” 是同义词。 OOP 的定义却让人感觉正好相反, 毫无疑问,OOP 让你定义 “对象”,将数据和代码绑定在一起。 与 C 这样的结构化语言相比,与 Scheme 这样的函数语言相比, OOP 的特性是它将状态和行为紧紧地绑在一起。
你也许认为类是完成这个的唯一方式方法, 但是包括 Dave Ungar 和 Randall Smith 的一大堆家伙一直在拼命区分 OOP 和类。 他们在 80 年代创建了一种叫做 Self 的语言。它不用类实现了 OOP。
Self 语言
就单纯意义而言,Self 比基于类的语言更加面向对象。 我们认为 OOP 将状态和行为绑在一起,但是基于类的语言实际将状态和行为割裂开来。
拿你最喜欢的基于类的语言的语法来说。 为了接触对象中的一些状态,你需要在实例的内存中查询。状态包含在实例中。
但是,为了调用方法,你需要找到实例的类, 然后在那里调用方法。行为包含在类中。 获得方法总需要通过中间层,这意味着字段和方法是不同的。

举个例子,为了调用 C++ 中的虚方法,你需要在实例中找指向虚方法表的指针,然后再在那里找方法。
Self 结束了这种分歧。无论你要找啥,都只需在对象中找。 实例同时包含状态和行为。你可以构建拥有完全独特方法的对象。

没有人能与世隔绝,但这个对象是。
如果这就是 Self 语言的全部,那它将很难使用。 基于类的语言中的继承,不管有多少缺陷,总归提供了有用的机制来重用代码,避免重复。 为了不使用类而实现一些类似的功能,Self 语言加入了委托。
如果要在对象中寻找字段或者调用方法,首先在对象内部查找。 如果能找到,那就成了。如果找不到,在对象的父对象中寻找。 这里的父类仅仅是一个对其他对象的引用。 当我们没能在第一个对象中找到属性,我们尝试它的父对象,然后父类的父对象,继续下去直到找到或者没有父对象为止。 换言之,失败的查找被委托给对象的父对象。
我在这里简化了。Self 实际上支持多个父对象。 父对象只是特别标明的字段,意味着你可以继承它们或者在运行时改变他们, 你最终得到了 “动态继承”。

父对象让我们在不同对象间重用行为(还有状态!),这样就完成了类的公用功能。 类做的另一个关键事情就是给出了创建实例的方法。 当你需要新的某物,你可以直接 new Thingamabob(),或者随便什么你喜欢的表达法。 类是实例的生产工厂。
不用类,我们怎样创建新的实例? 特别地,我们如何创建一堆有共同点的新东西? 就像这个设计模式,在 Self 中,达到这点的方式是使用克隆。
在 Self 语言中,就好像每个对象都自动支持原型设计模式。 任何对象都能被克隆。为了获得一堆相似的对象,你:
- 将对象塑造成你想要的状态。你可以直接克隆系统内建的基本
Object,然后向其中添加字段和方法。 - 克隆它来产出…… 额…… 随你想要多少就克隆多少个对象。
无需烦扰自己实现 clone();我们就实现了优雅的原型模式,原型被内建在系统中。
这个系统美妙,灵巧,而且小巧, 一听说它,我就开始创建一个基于原型的语言来进一步学习。
我知道从头开始构建一种编程语言语言不是学习它最有效率的办法,但我能说什么呢?我可算是个怪人。 如果你很好奇,我构建的语言叫 Finch.
它的实际效果如何?
能使用纯粹基于原型的语言让我很兴奋,但是当我真正上手时, 我发现了一个令人不快的事实:用它编程没那么有趣。
从小道消息中,我听说很多 Self 程序员得出了相同的结论。 但这项目并不是一无是处。 Self 非常的灵活,为此创造了很多虚拟机的机制来保持高速运行。
他们发明了 JIT 编译,垃圾回收,以及优化方法分配 —— 这都是由同一批人实现的 —— 这些新玩意让动态类型语言能快速运行,构建了很多大受欢迎的应用。
是的,语言本身很容易实现,那是因为它把复杂度甩给了用户。 一旦开始试着使用这语言,我发现我想念基于类语言中的层次结构。 最终,在构建语言缺失的库概念时,我放弃了。
鉴于我之前的经验都来自基于类的语言,因此我的头脑可能已经固定在它的范式上了。 但是直觉上,我认为大部分人还是喜欢有清晰定义的 “事物”。
除去基于类的语言自身的成功以外,看看有多少游戏用类建模描述玩家角色,以及不同的敌人、物品、技能。 不是游戏中的每个怪物都与众不同,你不会看到 “洞穴人和哥布林还有雪混合在一起” 这样的怪物。
原型是非常酷的范式,我希望有更多人了解它, 但我很庆幸不必天天用它编程。 完全皈依原型的代码是一团浆糊,难以阅读和使用。
这同时证明,很少 有人使用原型风格的代码。我查过了。
JavaScript 又怎么样呢?
好吧,如果基于原型的语言不那么友好,怎么解释 JavaScript 呢? 这是一个有原型的语言,每天被数百万人使用。运行 JavaScript 的机器数量超过了地球上其他所有的语言。
Brendan Eich,JavaScript 的缔造者, 从 Self 语言中直接汲取灵感,很多 JavaScript 的语义都是基于原型的。 每个对象都有属性的集合,包含字段和 “方法”(事实上只是存储为字段的函数)。 A 对象可以拥有 B 对象,B 对象被称为 A 对象的 “原型”, 如果 A 对象的字段获取失败就会委托给 B 对象。
作为语言设计者,原型的诱人之处是它们比类更易于实现。 Eich 充分利用了这一点,他在十天内创建了 JavaScript 的第一个版本。
但除那以外,我相信在实践中,JavaScript 更像是基于类的而不是基于原型的语言。 JavaScript 与 Self 有所偏离,其中一个要点是除去了基于原型语言的核心操作 “克隆”。
在 JavaScript 中没有方法来克隆一个对象。 最接近的方法是 Object.create(),允许你创建新对象作为现有对象的委托。 这个方法在 ECMAScript5 中才添加,而那已是 JavaScript 出现后的第十四年了。 相对于克隆,让我带你参观一下 JavaScript 中定义类和创建对象的经典方法。 我们从构造器函数开始:
function Weapon(range, damage) { |
这创建了一个新对象,初始化了它的字段。你像这样引入它:
var sword = new Weapon(10, 16); |
这里的 new 调用 Weapon() 函数,而 this 绑定在新的空对象上。 函数为新对象添加了一系列字段,然后返回填满的对象。
new 也为你做了另外一件事。 当它创建那个新的空对象时,它将空对象的委托和一个原型对象连接起来。 你可以用 Weapon.prototype 来获得原型对象。
属性是添加到构造器中的,而定义行为通常是通过向原型对象添加方法。就像这样:
Weapon.prototype.attack = function(target) { |
这给武器原型添加了 attack 属性,其值是一个函数。 由于 new Weapon() 返回的每一个对象都有给 Weapon.prototype 的委托, 你现在可以通过调用 sword.attack() 来调用那个函数。 看上去像是这样:

让我们复习一下:
- 通过 “new” 操作创建对象,该操作引入代表类型的对象 —— 构造器函数。
- 状态存储在实例中。
- 行为通过间接层 —— 原型的委托 —— 被存储在独立的对象中,代表了一系列特定类型对象的共享方法。
说我疯了吧,但这听起来很像是我之前描述的类。 你可以在 JavaScript 中写原型风格的代码(不用 克隆), 但是语言的语法和惯用法更鼓励基于类的实现。
个人而言,我认为这是好事。 就像我说的,我发现如果一切都使用原型,就很难编写代码, 所以我喜欢 JavaScript,它将整个核心语义包上了一层糖衣。
为数据模型构建原型
好吧,我之前不断地讨论我不喜欢原型的原因,这让这一章读起来令人沮丧。 我认为这本书应该更欢乐些,所以在最后,让我们讨论讨论原型确实有用,或者更加精确,委托 有用的地方。
随着编程的进行,如果你比较程序与数据的字节数, 那么你会发现数据的占比稳定地增长。 早期的游戏在程序中生成几乎所有东西,这样程序可以塞进磁盘和老式游戏卡带。 在今日的游戏中,代码只是驱动游戏的 “引擎”,游戏是完全由数据定义的。
这很好,但是将内容推到数据文件中并不能魔术般地解决组织大项目的挑战。 它只能把这挑战变得更难。 我们使用编程语言就因为它们有办法管理复杂性。
不再是将一堆代码拷来拷去,我们将其移入函数中,通过名字调用。 不再是在一堆类之间复制方法,我们将其放入单独的类中,让其他类可以继承或者组合。
当游戏数据达到一定规模时,你真的需要考虑一些相似的方案。 我不指望在这里能说清数据模式这个问题, 但我确实希望提出个思路,让你在游戏中考虑考虑:使用原型和委托来重用数据。
假设我们为早先提到的山寨版《圣铠传说》定义数据模型。 游戏设计者需要在很多文件中设定怪物和物品的属性。
这标题是我原创的,没有受到任何已存的多人地下城游戏的影响。 请不要起诉我。
一个常用的方法是使用 JSON。 数据实体一般是字典,或者属性集合,或者其他什么术语, 因为程序员就喜欢为旧事物发明新名字。
我们重新发明了太多次,Steve Yegge 称之为 “通用设计模式”.
所以游戏中的哥布林也许被定义为像这样的东西:
{ |
这看上去很易懂,哪怕是最讨厌文本的设计者也能使用它。 所以,你可以给哥布林大家族添加几个兄弟分支:
{ |
现在,如果这是代码,我们会闻到了臭味。 在实体间有很多的重复,训练优良的程序员讨厌重复。 它浪费了空间,消耗了作者更多时间。 你需要仔细阅读代码才知道这些数据是不是相同的。 这难以维护。 如果我们决定让所有哥布林变强,需要记得将三个哥布林都更新一遍。糟糕糟糕糟糕。
如果这是代码,我们会为 “哥布林” 构建抽象,并在三个哥布林类型中重用。 但是无能的 JSON 没法这么做。所以让我们把它做得更加巧妙些。
我们可以为对象添加 "prototype" 字段,记录委托对象的名字。 如果在此对象内没找到一个字段,那就去委托对象中查找。
这让
"prototype"不再是数据,而成为了元数据。 哥布林有绿色疣皮和黄色牙齿。 它们没有原型。 原型是表示哥布林的数据模型的属性,而不是哥布林本身的属性。
这样,我们可以简化我们的哥布林 JSON 内容:
{ |
由于弓箭手和术士都将 grunt 作为原型,我们就不需要在它们中重复血量,防御和弱点。 我们为数据模型增加的逻辑超级简单 —— 基本的单一委托 —— 但已经成功摆脱了一堆冗余。
有趣的事情是,我们没有更进一步,把哥布林委托的抽象原型设置成 “基本哥布林”。 相反,我们选择了最简单的哥布林,然后委托给它。
在基于原型的系统中,对象可以克隆产生新对象是很自然的, 我认为在这里也一样自然。这特别适合记录那些只有一处不同的实体的数据。
想想 Boss 和其他独特的事物,它们通常是更加常见事物的重新定义, 原型委托是定义它们的好方法。 断头魔剑,就是一把拥有加成的长剑,可以像下面这样表示:
{ |
只需在游戏引擎上多花点时间,你就能让设计者更加方便地添加不同的武器和怪物,而增加的这些丰富度能够取悦玩家。
单例模式
这个章节不同寻常。 其他章节展示如何使用某个设计模式。 这个章节展示如何避免使用某个设计模式。
尽管它的意图是好的,GoF 描述的单例模式通常弊大于利。 他们强调应该谨慎使用这个模式,但在游戏业界的口口相传中,这一提示经常被无视了。
就像其他模式一样,在不合适的地方使用单例模式就好像用夹板处理子弹伤口。 由于它被滥用得太严重了,这章的大部分都在讲如何回避单例模式, 但首先,让我们看看模式本身。
当业界从 C 语言迁移到面向对象的语言,他们遇到的首个问题是 “如何访问实例?” 他们知道有要调用的方法,但是找不到实例提供这个方法。 单例(换言之,全局化)是一条简单的解决方案。
单例模式
设计模式 像这样描述单例模式:
保证一个类只有一个实例,并且提供了访问该实例的全局访问点。
我们从 “并且” 那里将句子分为两部分,分别进行考虑。
保证一个类只有一个实例
有时候,如果类存在多个实例就不能正确的运行。 通常发生在类与保存全局状态的外部系统互动时。
考虑封装文件系统的 API 类。 因为文件操作需要一段时间完成,所以类使用异步操作。 这就意味着可以同时运行多个操作,必须让它们相互协调。 如果一个操作创建文件,另一个操作删除同一文件,封装器类需要同时考虑,保证它们没有相互妨碍。
为了实现这点,对我们封装器类的调用必须接触之前的每个操作。 如果用户可以自由地创建类的实例,这个实例就无法知道另一实例之前的操作。 而单例模式提供的构建类的方式,在编译时保证类只有单一实例。
提供了访问该实例的全局访问点
游戏中的不同系统都会使用文件系统封装类:日志,内容加载,游戏状态保存,等等。 如果这些系统不能创建文件系统封装类的实例,它们如何访问该实例呢?
单例为这点也提供了解决方案。 除了创建单一实例以外,它也提供了一种获得它的全局方法。 使用这种范式,无论何处何人都可以访问实例。 综合起来,经典的实现方案如下:
class FileSystem |
静态的 instance_成员保存了一个类的实例, 私有的构造器保证了它是唯一的。 公开的静态方法 instance() 让任何地方的代码都能访问实例。 在首次被请求时,它同样负责惰性实例化该单例。
现代的实现方案看起来是这样的:
class FileSystem |
哪怕是在多线程情况下,C++11 标准也保证了本地静态变量只会初始化一次, 因此,假设你有一个现代 C++ 编译器,这段代码是线程安全的,而前面的那个例子不是。
当然,单例类本身的线程安全是个不同的问题!这里只保证了它的初始化没问题。
为什么我们使用它
看起来已有成效。 文件系统封装类在任何需要的地方都可用,而无需笨重地到处传递。 类本身巧妙地保证了我们不会实例化多个实例而搞砸。它还具有很多其他的优良性质:
如果没人用,就不必创建实例。 节约内存和 CPU 循环总是好的。 由于单例只在第一次被请求时实例化,如果游戏永远不请求,那么它不会被实例化。
它在运行时实例化。 通常的替代方案是使用含有静态成员变量的类。 我喜欢简单的解决方案,因此我尽可能使用静态类而不是单例,但是静态成员有个限制:自动初始化。 编译器在
main()运行前初始化静态变量。 这就意味着不能使用在程序加载时才获取的信息(举个例子,从文件加载的配置)。 这也意味着它们的相互依赖是不可靠的 —— 编译器可不保证以什么样的顺序初始化静态变量。惰性初始化解决了以上两个问题。 单例会尽可能晚地初始化,所以那时它需要的所有信息都应该可用了。 只要没有环状依赖,一个单例在初始化它自己的时甚至可以引用另一个单例。
可继承单例。 这是个很有用但通常被忽视的能力。 假设我们需要跨平台的文件系统封装类。 为了达到这一点,我们需要它变成文件系统抽象出来的接口,而子类为每个平台实现接口。 这是基类:
class FileSystem
{
public:
virtual ~FileSystem() {}
virtual char* readFile(char* path) = 0;
virtual void writeFile(char* path, char* contents) = 0;
};然后为一堆平台定义子类:
class PS3FileSystem : public FileSystem
{
public:
virtual char* readFile(char* path)
{
// 使用索尼的文件读写API……
}
virtual void writeFile(char* path, char* contents)
{
// 使用索尼的文件读写API……
}
};
class WiiFileSystem : public FileSystem
{
public:
virtual char* readFile(char* path)
{
// 使用任天堂的文件读写API……
}
virtual void writeFile(char* path, char* contents)
{
// 使用任天堂的文件读写API……
}
};下一步,我们把
FileSystem变成单例:class FileSystem
{
public:
static FileSystem& instance();
virtual ~FileSystem() {}
virtual char* readFile(char* path) = 0;
virtual void writeFile(char* path, char* contents) = 0;
protected:
FileSystem() {}
};灵巧之处在于如何创建实例:
FileSystem& FileSystem::instance()
{
static FileSystem *instance = new PS3FileSystem();
static FileSystem *instance = new WiiFileSystem();
return *instance;
}
通过一个简单的编译器转换,我们把文件系统包装类绑定到合适的具体类型上。 整个代码库都可以使用 FileSystem::instance() 接触到文件系统,而无需和任何平台相关的代码耦合。耦合发生在为特定平台写的 FileSystem 类实现文件中。
大多数人解决问题到这个程度就已经够了。 我们得到了一个文件系统封装类。 它工作可靠,它全局有效,只要请求就能获取。 是时候提交代码,开怀畅饮了。
为什么我们后悔使用它
短期来看,单例模式是相对良性的。 就像其他设计决策一样,我们需要从长期考虑。 这里是一旦我们将一些不必要的单例写进代码,会给自己带来的麻烦:
它是一个全局变量
当游戏还是由几个家伙在车库中完成时,榨干硬件性能比象牙塔里的软件工程原则更重要。 C 语言和汇编程序员前辈能毫无问题地使用全局变量和静态变量,发布好游戏。 但随着游戏变得越来越大,越来越复杂,架构和管理开始变成瓶颈, 阻碍我们发布游戏的,除了硬件限制,还有生产力限制。
所以我们迁移到了像 C++ 这样的语言, 开始将一些从软件工程师前辈那里学到的智慧应用于实际。 其中一课是全局变量有害的诸多原因:
理解代码更加困难。 假设我们在查找其他人所写函数中的漏洞。 如果函数没有碰到任何全局状态,脑子只需围着函数转, 只需搞懂函数和传给函数的变量。
计算机科学家称不接触不修改全局状态的函数为 “纯” 函数。 纯函数易于理解,易于编译器优化, 易于完成优雅的任务,比如记住缓存的情况并继续上次调用。
完全使用纯函数是有难度的,但其好处足以引诱科学家创造像 Haskell 这样只使用纯函数的语言。
现在考虑函数中间是个对
SomeClass::getSomeGlobalData()的调用。为了查明发生了什么,得追踪整个代码库来看看什么修改了全局变量。你真的不需要讨厌全局变量,直到你在凌晨三点使用grep搜索数百万行代码,搞清楚哪一个错误的调用将一个静态变量设为了错误的值。计算机科学家称不接触不修改全局状态的函数为 “纯” 函数。 纯函数易于理解,易于编译器优化, 易于完成优雅的任务,比如记住缓存的情况并继续上次调用。
完全使用纯函数是有难度的,但其好处足以引诱科学家创造像 Haskell 这样只使用纯函数的语言。
促进了耦合的发生。 新加入团队的程序员也许不熟悉你们完美、可维护、松散耦合的游戏架构, 但还是刚刚获得了第一个任务:在岩石撞击地面时播放声音。 你我都知道这不需要将物理和音频代码耦合,但是他只想着把任务完成。 不幸的是,我们的
AudioPlayer是全局可见的。 所以之后一个小小的#include,新队员就打乱了整个精心设计的架构。如果不用全局实例实现音频播放器,那么哪怕他确实用
#include包含了头文件,他还是啥也做不了。 这种阻碍给他发送了一个明确的信号,这两个模块不该接触,他需要另辟蹊径。通过控制对实例的访问,你控制了耦合。对并行不友好。 那些在单核 CPU 上运行游戏的日子已经远去。 哪怕完全不需要并行的优势,现代的代码至少也应考虑在多线程环境下工作。 当我们将某些东西转为全局变量时,我们创建了一块每个线程都能看到并访问的内存, 却不知道其他线程是否正在使用那块内存。 这种方式带来了死锁,竞争状态,以及其他很难解决的线程同步问题。
像这样的问题足够吓阻我们声明全局变量了, 同理单例模式也是一样,但是那还没有告诉我们应该如何设计游戏。 怎样不使用全局变量构建游戏?
有几个对这个问题的答案(这本书的大部分都是由答案构成), 但是它们并非显而易见。 与此同时,我们得发布游戏。 单例模式看起来是万能药。 它被写进了一本关于面向对象设计模式的书中,因此它肯定是个好的设计模式,对吧? 况且我们已经借助它做了很多年软件设计了。
不幸的是,它不是解药,它是安慰剂。 如果浏览全局变量造成的问题列表,你会注意到单例模式解决不了其中任何一个。 因为单例确实是全局状态 —— 它只是被封装在一个类中。
它能在你只有一个问题的时候解决两个
在 GoF 对单例模式的描述中,“并且” 这个词有点奇怪。 这个模式解决了一个问题还是两个问题呢?如果我们只有其中一个问题呢? 保证实例是唯一存在的是很有用的,但是谁告诉我们要让每个人都能接触到它? 同样,全局接触很方便,但是必须禁止存在多个实例吗?
这两个问题中的后者,便利的访问,几乎是使用单例模式的全部原因。 想想日志类。大部分模块都能从记录诊断日志中获益。 但是,如果将 Log 类的实例传给每个需要这个方法的函数,那就混杂了产生的数据,模糊了代码的意图。
明显的解决方案是让 Log 类成为单例。 每个函数都能从类那里获得一个实例。 但当我们这样做时,我们无意地制造了一个奇怪的小约束。 突然之间,我们不再能创建多个日志记录者了。
起初,这不是一个问题。 我们记录单独的日志文件,所以只需要一个实例。 然后,随着开发周期的逐次循环,我们遇到了麻烦。 每个团队的成员都使用日志记录各自的诊断信息,大量的日志倾泻在文件里。 程序员需要翻过很多页代码来找到他关心的记录。
我们想将日志分散到多个文件中来解决这点。 为了达到这点,我们得为游戏的不同领域创造单独的日志记录者: 网络,UI,声音,游戏,玩法。 但是我们做不到。 Log 类不再允许我们创建多个实例,而且调用的方式也保证了这一点:
Log::instance().write("Some event."); |
为了让 Log 类支持多个实例(就像它原来的那样), 我们需要修改类和提及它的每一行代码。 之前便利的访问就不再那么便利了。
这可能更糟。想象一下你的 Log 类是在多个游戏间共享的库中。 现在,为了改变设计,需要在多组人之间协调改变, 他们中的大多数既没有时间,也没有动机修复它。
惰性初始化从你那里剥夺了控制权
在拥有虚拟内存和软性性能需求的 PC 里,惰性初始化是一个小技巧。 游戏则是另一种状况。初始化系统需要消耗时间:分配内存,加载资源,等等。 如果初始化音频系统消耗了几百个毫秒,我们需要控制它何时发生。 如果在第一次声音播放时惰性初始化它自己,这可能发生在游戏的高潮部分,导致可见的掉帧和断续的游戏体验。
同样,游戏通常需要严格管理在堆上分配的内存来避免碎片。 如果音频系统在初始化时分配到了堆上,我们需要知道初始化在何时发生, 这样我们可以控制内存待在堆的哪里。
对象池模式一节中有内存碎片的其他细节。
因为这两个原因,我见到的大多数游戏都不使用惰性初始化。 相反,它们像这样实现单例模式:
class FileSystem |
这解决了惰性初始化问题,但是损失了几个单例确实比原生的全局变量优良的特性。 静态实例中,我们不能使用多态,在静态初始化时,类也必须是可构建的。 我们也不能在不需要这个实例的时候,释放实例所占的内存。
与创建一个单例不同,这里实际上是一个简单的静态类。 这并非坏事,但是如果你需要的是静态类,为什么不完全摆脱 instance() 方法, 直接使用静态函数呢?调用 Foo::bar() 比 Foo::instance().bar() 更简单, 也更明确地表明你在处理静态内存。
通常使用单例而不是静态类的理由是, 如果你后来决定将静态类改为非静态的,你需要修改每一个调用点。 理论上,用单例就不必那么做,因为你可以将实例传来传去,像普通的实例方法一样使用。
实践中,我从未见过这种情况。 每个人都在使用 Foo::instance().bar()。 如果我们将 Foo 改成非单例,我们还是得修改每一个调用点。 鉴于此,我更喜欢简单的类和简单的调用语法。
那该如何是好
如果我现在达到了目标,你在下次遇到问题使用单例模式之前就会三思而后行。 但是你还是有问题需要解决。你应该使用什么工具呢? 这取决于你试图做什么,我有一些你可以考虑的选项,但是首先……
看看你是不是真正地需要类
我在游戏中看到的很多单例类都是 “管理器”—— 那些类存在的意义就是照顾其他对象。 我曾看到一些代码库中,几乎所有类都有管理器: 怪物,怪物管理器,粒子,粒子管理器,声音,声音管理器,管理管理器的管理器。 有时候,它们被叫做 “系统” 或 “引擎”,但是思路还是一样的。
管理器类有时是有用的,但通常它们只是反映出作者对 OOP 的不熟悉。思考这两个特制的类:
class Bullet |
也许这个例子有些蠢,但是我见过很多代码,在剥离了外部的细节后是一样的设计。 如果你看看这个代码,BulletManager 很自然应是一个单例。 无论如何,任何有 Bullet 的对象都需要管理,而你又需要多少个 BulletManager 实例呢?
事实上,这里的答案是零。 这里是我们如何为管理类解决 “单例” 问题:
class Bullet |
好了。没有管理器,也没有问题。 糟糕设计的单例通常会 “帮助” 另一个类增加代码。 如果可以,把所有的行为都移到单例帮助的类中。 毕竟,OOP 就是让对象管理好自己。
但是在管理器之外,还有其他问题我们需要寻求单例模式帮助。 对于每种问题,都有一些后续方案可供参考。
将类限制为单一的实例
这是单例模式帮你解决的一个问题。 就像在文件系统的例子中那样,保证类只有一个实例是很重要的。 但是,这不意味着我们需要提供对实例的公众,全局访问。 我们想要减少某部分代码的公众部分,甚至让它在类中是私有的。 在这些情况下,提供一个全局接触点消弱了整体架构。
举个例子,我们也许想把文件系统包在另一层抽象中。
我们希望有种方式能保证同事只有一个实例而无需提供全局接触点。 有好几种方法能做到。这是其中之一:
class FileSystem |
这个类允许任何人构建它,如果你试图构建超过一个实例,它会断言并失败。 只要正确的代码首先创建了实例,那么就保证了没有其他代码可以接触实例或者创建自己的实例。 这个类保证满足了它关注的单一实例,但是它没有指定类该如何被使用。
断言 函数是一种向你的代码中添加限制的方法。 当 assert() 被调用时,它计算传入的表达式。 如果结果为 true,那么什么都不做,游戏继续。 如果结果为 false,它立刻停止游戏。 在 debug build 时,这通常会启动调试器,或至少打印失败断言所在的文件和行号。
assert() 表示, “我断言这个总该是真的。如果不是,那就是漏洞,我想立刻停止并处理它。” 这使得你可以在代码区域之间定义约束。 如果函数断言它的某个参数不能为 NULL,那就是说,“我和调用者定下了协议:传入的参数不会 NULL。”
断言帮助我们在游戏发生预期以外的事时立刻追踪漏洞, 而不是等到错误最终显现在用户可见的某些事物上。 它们是代码中的栅栏,围住漏洞,这样漏洞就不能从制造它的代码边逃开。
这个实现的缺点是只在运行时检查并阻止多重实例化。 单例模式正相反,通过类的自然结构,在编译时就能确定实例是单一的。
为了给实例提供方便的访问方法
便利的访问是我们使用单例的一个主要原因。 这让我们在不同地方获取需要的对象更加容易。 这种便利是需要付出代价的 —— 在我们不想要对象的地方,也能轻易地使用。
通用原则是在能完成工作的同时,将变量写得尽可能局部。 对象影响的范围越小,在处理它时,我们需要放在脑子里的东西就越少。 在我们拿起有全局范围影响的单例对象前,先考虑考虑代码中其他获取对象的方式:
传进来。 最简单的解决办法,通常也是最好的,把你需要的对象简单地作为参数传给需要它的函数。 在用其他更加繁杂的方法前,考虑一下这个解决方案。
有些人使用术语 “依赖注入” 来指代它。不是代码出来调用某些全局量来确认依赖, 而是依赖通过参数被传进到需要它的代码中去。 其他人将 “依赖注入” 保留为对代码提供更复杂依赖的方法。
考虑渲染对象的函数。为了渲染,它需要接触一个代表图形设备的对象,管理渲染状态。 将其传给所有渲染函数是很自然的,通常是用一个名字像
context之类的参数。另一方面,有些对象不该在方法的参数列表中出现。 举个例子,处理 AI 的函数可能也需要写日志文件,但是日志不是它的核心关注点。 看到
Log出现在它的参数列表中是很奇怪的事情,像这样的情况,我们需要考虑其他的选项。像日志这样散布在代码库各处的是 “横切关注点”(cross-cutting concern)。 小心地处理横切关注点是架构中的持久挑战,特别是在静态类型语言中。
面向切面编程被设计出来应对它们。
从基类中获得。 很多游戏架构有浅层但是宽泛的继承层次,通常只有一层深。 举个例子,你也许有
GameObject基类,每个游戏中的敌人或者对象都继承它。 使用这样的架构,很大一部分游戏代码会存在于这些 “子” 推导类中。 这就意味着这些类已经有了对同样事物的相同获取方法:它们的GameObject基类。 我们可以利用这点:class GameObject
{
protected:
Log& getLog() { return log_; }
private:
static Log& log_;
};
class Enemy : public GameObject
{
void doSomething()
{
getLog().write("I can log!");
}
};这保证任何
GameObject之外的代码都不能接触Log对象,但是每个派生的实体都确实能使用getLog()。 这种使用 protected 函数,让派生对象使用的模式, 被涵盖在子类沙箱这章中。这也引出了一个新问题,“
GameObject是怎样获得Log实例的?” 一个简单的方案是,让基类创建并拥有静态实例。如果你不想要基类承担这些,你可以提供一个初始化函数传入
Log实例, 或使用服务定位器模式找到它。从已经是全局的东西中获取。 移除所有全局状态的目标令人钦佩,但并不实际。 大多数代码库仍有一些全局可用对象,比如一个代表了整个游戏状态的
Game或World对象。我们可以让现有的全局对象捎带需要的东西,来减少全局变量类的数目。 不让
Log,FileSystem和AudioPlayer都变成单例,而是这样做:class Game
{
public:
static Game& instance() { return instance_; }
// 设置log_, et. al. ……
Log& getLog() { return *log_; }
FileSystem& getFileSystem() { return *fileSystem_; }
AudioPlayer& getAudioPlayer() { return *audioPlayer_; }
private:
static Game instance_;
Log *log_;
FileSystem *fileSystem_;
AudioPlayer *audioPlayer_;
};这样,只有
Game是全局可见的。 函数可以通过它访问其他系统。Game::instance().getAudioPlayer().play(VERY_LOUD_BANG);
纯粹主义者会声称这违反了 Demeter 法则。我则声称这比一大坨单例要好。
如果,稍后,架构被改为支持多个
Game实例(可能是为了流处理或者测试),Log,FileSystem,和AudioPlayer都不会被影响到 —— 它们甚至不知道有什么区别。 缺陷是,当然,更多的代码耦合到了Game中。 如果一个类简单地需要播放声音,为了访问音频播放器,上例中仍然需要它知道游戏世界。我们通过混合方案解决这点。 知道
Game的代码可以直接从它那里访问AudioPlayer。 而不知道的代码,我们用上面描述的其他选项来提供AudioPlayer。从服务定位器中获得。 目前为止,我们假设全局类是具体的类,比如 Game。 另一种选项是定义一个类,存在的唯一目标就是为对象提供全局访问。 这种常见的模式被称为服务定位器模式,有单独讲它的章节。
单例中还剩下什么
剩下的问题,何处我们应该使用真实的单例模式? 说实话,我从来没有在游戏中使用全部的 GoF 模式。 为了保证实例是单一的,我通常简单地使用静态类。 如果这无效,我使用静态标识位,在运行时检测是不是只有一个实例被创建了。
书中还有一些其他章节也许能有所帮助。 子类沙箱模式通过分享状态, 给实例以类的访问权限而无需让其全局可用。 服务定位器模式确实让一个对象全局可用, 但它给了你如何设置对象的灵活性。
状态模式
忏悔时间:我有些越界,将太多的东西打包到了这章中。 它表面上关于状态模式, 但我无法只讨论它和游戏,而不涉及更加基础的有限状态机(FSMs)。 但是一旦讲了那个,我发现也想要介绍层次状态机和下推自动机。
有很多要讲,我会尽可能简短,这里的示例代码留下了一些你需要自己填补的细节。 我希望它们仍然足够清晰,能让你获取一份全景图。
如果你从来没有听说过状态机,不要难过。 虽然在 AI 和编译器程序方面很出名,但它在其他编程圈就没那么知名了。 我认为应该有更多人知道它,所以在这里我将其运用在不同的问题上。
这些状态机术语来自人工智能的早期时代。 在五十年代到六十年代,很多 AI 研究关注于语言处理。 很多现在用于分析程序语言的技术在当时是发明出来分析人类语言的。
感同身受
假设我们在完成一个卷轴平台游戏。 现在的工作是实现玩家在游戏世界中操作的女英雄。 这就意味着她需要对玩家的输入做出响应。按 B 键她应该跳跃。简单实现如下:
void Heroine::handleInput(Input input) |
看到漏洞了吗?
没有东西阻止 “空中跳跃”—— 当角色在空中时狂按 B,她就会浮空。 简单的修复方法是给 Heroine 增加 isJumping_布尔字段,追踪它跳跃的状态。然后这样做:
void Heroine::handleInput(Input input) |
这里也应该有在英雄接触到地面时将 isJumping_设回 false 的代码。 我在这里为了简明没有写。
接下来,当玩家按下下方向键时,如果角色在地上,我们想要她卧倒,而松开按键时站起来:
void Heroine::handleInput(Input input) |
这次看到漏洞了吗?
通过这个代码,玩家可以:
- 按下键卧倒。
- 按 B 从卧倒状态跳起。
- 在空中放开下键。
英雄跳一半贴图变成了站立时的贴图。是时候增加另一个标识了……
void Heroine::handleInput(Input input) |
下面,如果玩家在跳跃途中按下下方向键,英雄能够做跳斩攻击就太酷了:
void Heroine::handleInput(Input input) |
又是检查漏洞的时间了。找到了吗?
跳跃时我们检查了字段,防止了空气跳,但是速降时没有。又是另一个字段……
我们的实现方法很明显有错。 每次我们改动代码时,就破坏些东西。 我们需要增加更多动作 —— 行走 都还没有加入呢 —— 但以这种做法,完成之前就会造成一堆漏洞。
那些你崇拜的、看上去永远能写出完美代码的程序员并不是超人。 相反,他们有哪种代码易于出错的直觉,然后避开。
复杂分支和可变状态 —— 随时间改变的字段 —— 是两种易错代码,上面的例子覆盖了两者。
有限状态机前来救援
在经历了上面的挫败之后,把桌子扫空,只留下纸笔,我们开始画流程图。 你给英雄每件能做的事情都画了一个盒子:站立,跳跃,俯卧,跳斩。 当角色在能响应按键的状态时,你从那个盒子画出一个箭头,标记上按键,然后连接到她变到的状态。

祝贺,你刚刚建好了一个有限状态机。 它来自计算机科学的分支自动理论,那里有很多著名的数据结构,包括著名的图灵机。 FSMs 是其中最简单的成员。
要点是:
你拥有状态机所有可能状态的集合。 在我们的例子中,是站立,跳跃,俯卧和速降。
状态机同时只能在一个状态。 英雄不可能同时处于跳跃和站立状态。事实上,防止这点是使用 FSM 的理由之一。
一连串的输入或事件被发送给状态机。 在我们的例子中,就是按键按下和松开。
每个状态都有一系列的转移,每个转移与输入和另一状态相关。 当输入进来,如果它与当前状态的某个转移相匹配,机器转换为所指的状态。
举个例子,在站立状态时,按下下方向键转换为俯卧状态。 在跳跃时按下下方向键转换为速降。 如果输入在当前状态没有定义转移,输入就被忽视。
这就是核心部分的全部了:状态,输入,和转移。 你可以用一张流程图把它画出来。不幸的是,编译器不认识流程图, 所以我们如何实现一个? GoF 的状态模式是一个方法 —— 我们会谈到的 —— 但先从简单的开始。
对 FSMs 我最喜欢的类比是那种老式文字冒险游戏,比如 Zork。 你有个由屋子组成的世界,屋子彼此通过出口相连。你输入像 “去北方” 的导航指令探索屋子。
这其实就是状态机:每个屋子都是一个状态。 你现在在的屋子是当前状态。每个屋子的出口是它的转移。 导航指令是输入。
枚举和分支
Heroine 类的问题在于它不合法地捆绑了一堆布尔量: isJumping_和 isDucking_不会同时为真。 但有些标识同时只能有一个是 true,这提示你真正需要的其实是 enum(枚举)。
在这个例子中的 enum 就是 FSM 的状态的集合,所以让我们这样定义它:
enum State |
不需要一堆标识,Heroine 只有一个 state_状态。 这里我们同时改变了分支顺序。在前面的代码中,我们先判断输入,然后 判断状态。 这让处理某个按键的代码集中到了一处,但处理某个状态的代码分散到了各处。 我们想让处理状态的代码聚在一起,所以先对状态做分支。这样的话:
void Heroine::handleInput(Input input) |
这看起来很普通,但是比起前面的代码是个很大的进步。 我们仍有条件分支,但简化了状态变化,将它变成了字段。 处理同一状态的所有代码都聚到了一起。 这是实现状态机最简单的方法,在某些情况下,这也不错。
重要的是,英雄不再会处于不合法状态。 使用布尔标识,很多可能存在的值的组合是不合法的。 通过
enum,每个值都是合法的。
但是,你的问题也许超过了这个解法的能力范围。 假设我们想增加一个动作动作,英雄可以俯卧一段时间充能,之后释放一次特殊攻击。 当她俯卧时,我们需要追踪充能的持续时间。
我们为 Heroine 添加了 chargeTime_字段,记录充能的时间长度。 假设我们已经有一个每帧都会调用的 update() 方法。在那里,我们添加:
void Heroine::update() |
如果你猜这就是更新方法模式,恭喜你答对了!
我们需要在她开始俯卧的时候重置计时器,所以我们修改 handleInput():
void Heroine::handleInput(Input input) |
总而言之,为了增加这个充能攻击,我们需要修改两个方法, 添加一个 chargeTime_字段到 Heroine,哪怕它只在俯卧时有意义。 我们更喜欢的是让所有相关的代码和数据都待在同一个地方。GoF 完成了这个。
状态模式
对于那些思维模式深深沉浸在面向对象的人,每个条件分支都是使用动态分配的机会(在 C++ 中叫做虚方法调用)。 我觉得那就太过于复杂化了。有时候一个 if 就能满足你的需要了。
这里有个历史遗留问题。 原先的面向对象传教徒,比如写《设计模式》的 GoF 和写《重构》的 Martin Fowler 都使用 Smalltalk。 那里,ifThen: 只是个由你在一定情况下使用的方法,该方法在 true 和 false 对象中以不同的方式实现。
但是在我们的例子中,面向对象确实是一个更好的方案。 这带领我们走向状态模式。GoF 这样描述状态模式:
允许一个对象在其内部状态发生变化时改变自己的行为,该对象看起来好像修改了它的类型
这可没太多帮助。我们的 switch 也完成了这一点。 它们描述的东西应用在英雄的身上实际是:
一个状态接口
首先,我们为状态定义接口。 状态相关的行为 —— 之前用 switch 的每一处 —— 都成为了接口中的虚方法。 在我们的例子中,那是 handleInput() 和 update():
class HeroineState |
为每个状态写个类
对于每个状态,我们定义一个类实现接口。它的方法定义了英雄在状态的行为。 换言之,从之前的 switch 中取出每个 case,将它们移动到状态类中。举个例子:
class DuckingState : public HeroineState |
注意我们也将 chargeTime_移出了 Heroine,放到了 DuckingState 类中。 这很好 —— 那部分数据只在这个状态有用,现在我们的对象模型显式反映了这一点。
状态委托
接下来,向 Heroine 添加指向当前状态的指针,放弃庞大的 switch,转向状态委托:
class Heroine |
为了 “改变状态”,我们只需要将 state_声明指向不同的 HeroineState 对象。 这就是状态模式的全部了。
这看上去有些像策略模式和类型对象模式。 在三者中,你都有一个主对象委托给下属。区别在于意图。
- 在策略模式中,目标是解耦主类和它的部分行为。
- 在类型对象中,目标是通过共享一个对相同类型对象的引用,让一系列对象行为相近。
- 在状态模式中,目标是让主对象通过改变委托的对象,来改变它的行为。
状态对象在哪里?
我这里掩掩藏了一些细节。为了改变状态,我们需要声明 state_指向新的状态, 但那个新状态又是从哪里来呢? 在 enum 实现中,这都不用过脑子 ——enum 实际上就像数字一样。 但是现在状态是类了,意味着我们需要指向实例。通常这有两种方案:
静态状态
如果状态对象没有其他数据字段, 那么它存储的唯一数据就是指向虚方法表的指针,用来调用它的方法。 在这种情况下,没理由产生多个实例。毕竟每个实例都完全一样。
如果你的状态没有字段,只有一个虚方法,你可以再简化这个模式。 将每个状态类替换成状态函数 —— 只是一个普通的顶层函数。 然后,主类中的 state_字段变成一个简单的函数指针。
在那种情况下,你可以用一个静态实例。 哪怕你有一堆 FSM 同时在同一状态上运行,它们也能指向同一实例,因为状态没有与状态机相关的部分。
这是享元模式。
在哪里放置静态实例取决于你。找一个合理的地方。 没什么特殊的理由,在这里我将它放在状态基类中。
class HeroineState |
每个静态字段都是游戏状态类的一个实例。为了让英雄跳跃,站立状态会这样做:
if (input == PRESS_B) |
实例化状态
有时没那么容易。静态状态对俯卧状态不起作用。 它有一个 chargeTime_字段,与正在俯卧的英雄特定相关。 在游戏中,如果只有一个英雄,那也行,但是如果要添加双人合作,同时在屏幕上有两个英雄,就有麻烦了。
在那种情况下,转换时需要创建状态对象。 这需要每个 FSM 拥有自己的状态实例。如果我们分配新状态, 那意味着我们需要释放当前的状态。 在这里要小心,由于触发变化的代码是当前状态中的方法,需要删除 this,因此需要小心从事。
相反,我们允许 HeroineState 中的 handleInput() 返回一个新状态。 如果它那么做了,Heroine 会删除旧的,然后换成新的,就像这样:
void Heroine::handleInput(Input input) |
这样,直到从之前的状态返回,我们才需要删除它。 现在,站立状态可以通过创建新实例转换为俯卧状态:
HeroineState* StandingState::handleInput(Heroine& heroine, |
如果可以,我倾向于使用静态状态,因为它们不会在状态转换时消耗太多的内存和 CPU。 但是,对于更多状态的事物,需要耗费一些精力来实现。
入口行为和出口行为
当你为状态动态分配内存时,你也许会担心碎片。 对象池模式可以帮上忙。
状态模式的目标是将状态的行为和数据封装到单一类中。 我们完成了一部分,但是还有一些未了之事。
当英雄改变状态时,我们也改变她的贴图。 现在,那部分代码在她转换前的状态中。 当她从俯卧转为站立,俯卧状态修改了她的贴图:
HeroineState* DuckingState::handleInput(Heroine& heroine, |
我们想做的是,每个状态控制自己的贴图。这可以通过给状态一个入口行为来实现:
class StandingState : public HeroineState |
在 Heroine 中,我们将处理状态改变的代码移动到新状态上调用:
void Heroine::handleInput(Input input) |
这让我们将俯卧代码简化为:
HeroineState* DuckingState::handleInput(Heroine& heroine, |
它做的所有事情就是转换到站立状态,站立状态控制贴图。 现在我们的状态真正地封装了。 关于入口行为的好事就是,当你进入状态时,不必关心你是从哪个状态转换来的。
大多数真正的状态图都有转为同一状态的多个转移。 举个例子,英雄在跳跃或跳斩后进入站立状态。 这意味着我们在转换发生的最后重复相同的代码。 入口行为很好地解决了这一点。
我们能,当然,扩展并支持出口行为。 这是在我们离开现有状态,转换到新状态之前调用的方法。
有什么收获?
我花了这么长时间向您推销 FSMs,现在我们来捋一捋。 我到现在讲的都是真的,FSM 能很好地解决一些问题。但它们最大的优点也是它们最大的缺点。
状态机通过使用有约束的结构来理清杂乱的代码。 你只需一个固定状态的集合,单一的当前状态,和一些硬编码的转换。
一个有限状态机甚至不是图灵完全的。 自动理论用一系列抽象模型描述计算,每种都比之前的复杂。 图灵机 是其中最具有表现力的模型之一。
“图灵完全” 意味着一个系统(通常是编程语言)足以在内部实现一个图灵机, 也就意味着,在某种程度上,所有的图灵完全具有同样的表现力。 FSMs 不够灵活,并不在其中。
如果你需要为更复杂的东西使用状态机,比如游戏 AI,你会撞到这个模型的限制上。 感谢上天,我们的前辈找到了一些方法来避免这些限制。我会在这一章的最后简单地浏览一下它们。
并发状态机
我们决定赋予英雄拿枪的能力。 当她拿着枪的时候,她还是能做她之前的任何事情:跑动,跳跃,跳斩,等等。 但是她在做这些的同时也要能开火。
如果我们执着于 FSM,我们需要翻倍现有状态。 对于每个现有状态,我们需要另一个她持枪状态:站立,持枪站立,跳跃,持枪跳跃, 你知道我的意思了吧。
多加几种武器,状态就会指数爆炸。 不但增加了大量的状态,也增加了大量的冗余: 持枪和不持枪的状态是完全一样的,只是多了一点负责射击的代码。
问题在于我们将两种状态绑定到了一个状态机上 —— 她做的和她携带的。 为了处理所有可能的组合,我们需要为每一对组合写一个状态。 修复方法很明显:使用两个单独的状态机。
如果她在做什么有 n 个状态,而她携带了什么有 m 个状态,要塞到一个状态机中, 我们需要 n × m 个状态。使用两个状态机,就只有 n + m 个。
我们保留之前记录她在做什么的状态机,不用管它。 然后定义她携带了什么的单独状态机。 Heroine 将会有两个 “状态” 引用,每个对应一个状态机,就像这样:
class Heroine |
为了便于说明,她的装备也使用了状态模式。 在实践中,由于装备只有两个状态,一个布尔标识就够了。
当英雄把输入委托给了状态,两个状态都需要委托:
void Heroine::handleInput(Input input) |
功能更完备的系统也许能让状态机销毁输入,这样其他状态机就不会收到了。 这能阻止两个状态机响应同一输入。
每个状态机之后都能响应输入,发生行为,独立于其它机器改变状态。 当两个状态集合几乎没有联系的时候,它工作得不错。
在实践中,你会发现状态有时需要交互。 举个例子,也许她在跳跃时不能开火,或者她在持枪时不能跳斩攻击。 为了完成这个,你也许会在状态的代码中做一些粗糙的 if 测试其他状态来协同, 这不是最优雅的解决方案,但这可以搞定工作。
分层状态机
再充实一下英雄的行为,她可能会有更多相似的状态。 举个例子,她也许有站立、行走、奔跑和滑铲状态。在这些状态中,按 B 跳,按下蹲。
如果使用简单的状态机实现,我们在每个状态中的都重复了代码。 如果我们能够实现一次,在多个状态间重用就好了。
如果这是面向对象的代码而不是状态机的,在状态间分享代码的方式是通过继承。 我们可以为 “在地面上” 定义一个类处理跳跃和速降。 站立、行走、奔跑和滑铲都从它继承,然后增加各自的附加行为。
它的影响有好有坏。 继承是一种有力的代码重用工具,但也在两块代码间建立了非常强的耦合。 这是重锤,所以请小心使用。
你会发现,这是个被称为分层状态机的通用结构。 状态可以有父状态(这让它变为子状态)。 当一个事件进来,如果子状态没有处理,它就会交给链上的父状态。 换言之,它像重载的继承方法那样运作。
事实上,如果我们使用状态模式实现 FSM,我们可以使用继承来实现层次。 定义一个基类作为父状态:
class OnGroundState : public HeroineState |
每个子状态继承它:
class DuckingState : public OnGroundState |
这当然不是唯一的实现层次的方法。 如果你没有使用 GoF 的状态模式,这可能不会有用。 相反,你可以显式的使用状态栈而不是单一状态来表示当前状态的父状态链。
栈顶的状态是当前状态,在他下面是它的直接父状态, 然后是那个父状态的父状态,以此类推。 当你需要状态的特定行为,你从栈的顶端开始, 然后向下寻找,直到某一个状态处理了它。(如果到底也没找到,就无视它。)
下推自动机
还有一种有限状态机的扩展也用了状态栈。 容易混淆的是,这里的栈表示的是完全不同的事物,被用于解决不同的问题。
要解决的问题是有限状态机没有任何历史的概念。 你记得正在什么状态中,但是不记得曾在什么状态。 没有简单的办法重回上一状态。
举个例子:早先,我们让无畏英雄武装到了牙齿。 当她开火时,我们需要新状态播放开火动画,发射子弹,产生视觉效果。 所以我们拼凑了一个 FiringState,不管现在是什么状态,都能在按下开火按钮时跳转为这个状态。
这个行为在多个状态间重复,也许是用层次状态机重用代码的好地方。
问题在于她射击后转换到的状态。 她可以在站立、奔跑、跳跃、跳斩时射击。 当射击结束,应该转换为她之前的状态。
如果我们固执于纯粹的 FSM,我们就已经忘了她之前所处的状态。 为了追踪之前的状态,我们定义了很多几乎完全一样的类 —— 站立开火,跑步开火,跳跃开火,诸如此类 —— 每个都有硬编码的转换,用来回到之前的状态。
我们真正想要的是,它会存储开火前所处的状态,之后能回想起来。 自动理论又一次能帮上忙了,相关的数据结构被称为下推自动机。
有限状态机有一个指向状态的指针,下推自动机有一栈指针。 在 FSM 中,新状态代替了之前的那个状态。 下推自动机不仅能完成那个,还能给你两个额外操作:
- 你可以将新状态压入栈中。“当前的” 状态总是在栈顶,所以你能转到新状态。 但它让之前的状态待在栈中而不是销毁它。
- 你可以弹出最上面的状态。这个状态会被销毁,它下面的状态成为新状态。

这正是我们开火时需要的。我们创建单一的开火状态。 当开火按钮在其他状态按下时,我们压入开火状态。 当开火动画结束,我们弹出开火状态,然后下推自动机自动转回之前的状态。
所以它们有多有用呢?
即使状态机有这些常见的扩展,它们还是很受限制。 这让今日游戏 AI 移向了更加激动人心的领域,比如 * 行为树和规划系统 * 。 如果你关注复杂 AI,这一整章只是为了勾起你的食欲。 你需要阅读其他书来满足你的欲望。
这不意味着有限状态机,下推自动机,和其他简单的系统没有用。 它们是特定问题的好工具。有限状态机在以下情况有用:
- 你有个实体,它的行为基于一些内在状态。
- 状态可以被严格地分割为相对较少的不相干项目。
- 实体响应一系列输入或事件。
在游戏中,状态机因在 AI 中使用而闻名,但是它也常用于其他领域, 比如处理玩家输入,导航菜单界面,分析文字,网络协议以及其他异步行为。